Audacity: analisi tecnica di un brano musicale
Audacity non è solo uno strumento gratuito per registrare e montare l’audio: con un po’ di attenzione, può diventare un vero e proprio laboratorio di analisi per capire cosa rende un brano ben suonato, ben mixato e ben masterizzato.
In questo articolo vedremo come analizzare un brano sotto vari aspetti tecnici fondamentali, senza bisogno di strumenti costosi o complicati.
🎧 Ascolta prima di analizzare
Il brano che useremo in tutti gli esempi è disponibile qui sotto. Ti invitiamo ad ascoltarlo prima di proseguire nella lettura:
La traccia è stata normalizzata a 0 dB per garantire confronti coerenti durante l’analisi del fattore di cresta e della dinamica. Le proporzioni tra i picchi e il contenuto RMS restano inalterate rispetto alla versione originale.
Fattore di cresta (Crest Factor)
Il fattore di cresta misura il rapporto tra il valore di picco (il punto più alto della forma d’onda) e il valore RMS (Root Mean Square, ovvero una media energetica del segnale). Questo valore ci dice quanto è dinamico un brano, ovvero quanto spazio c’è tra le parti più intense e quelle più deboli.
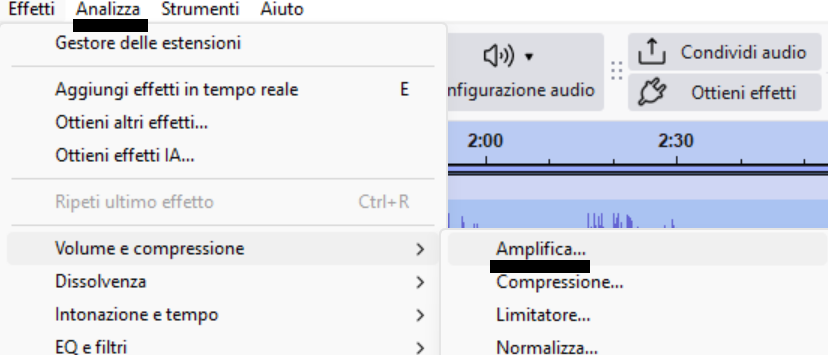
Come si calcola in Audacity
- Importa il brano in Audacity.
- Seleziona tutta la traccia (Ctrl+A).
- Vai su Effetti → Amplifica…
→ leggi il valore suggerito che indica l’amplificazione (o attenuazione) necessaria per portare il valore di picco massimo a 0 dB
→ quindi il picco massimo = − valore suggerito - Vai su Analizza → Statistiche (plugin RMS)
→ leggi il valore RMS - Calcola la differenza: Fattore di cresta (dB)= (Valore di picco ) – (Valore RMS)
Esempio
E otteniamo:
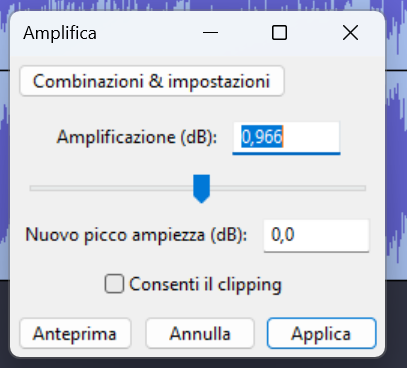
In questo caso abbiamo un valore suggerito positivo, potrebbe essere zero o negativo:
Approfondiamo il caso di un valore positivo (valore suggerito negativo)
In digitale, 0 dBFS è il massimo teorico possibile, tutto ciò che supera 0 dB in un file audio non dovrebbe esistere.
- Significa che il file contiene dei campioni che eccedono 0 dBFS.
- Questo succede quando:
- Il file è stato normalizzato o esportato senza limitazione.
- È stato ricampionato, effetti applicati male, o mal masterizzato.
- Oppure stiamo analizzando un file a 32-bit float, che può contenere valori oltre 0 dB senza clipping (è il nostro caso).
Come verificarlo:
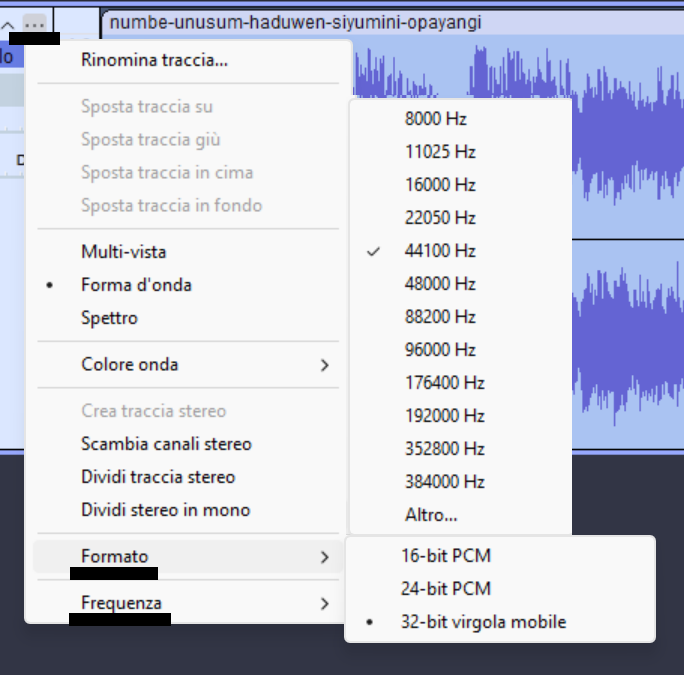
Il brano in esame è campionato a 44.100 Hz e utilizza un formato a 32 bit in virgola mobile. Audacity, infatti, lavora nativamente in 32-bit float per garantire la massima precisione durante l’elaborazione audio. Questo formato consente di rappresentare valori superiori a 0 dBFS senza introdurre clipping o distorsioni, rendendolo ideale per l’editing e il mixaggio, dove è importante evitare perdite di qualità nei passaggi intermedi. In sostanza, la traccia viene elaborata con una risoluzione superiore rispetto a quella che sarà effettivamente utilizzata nel file finale.
Al contrario, nei formati “a virgola fissa” come il PCM a 16 o 24 bit, ogni valore che supera 0 dBFS viene troncato, provocando clipping digitale udibile. Per questo motivo, se stiamo analizzando la traccia audio e il fattore di cresta, è fondamentale limitare o normalizzare il segnale a 0 dBFS prima di effettuare la misurazione, in modo da riflettere le condizioni reali di un file destinato all’ascolto o alla distribuzione.
Per standardizzare il brano e renderlo più simile a un formato mp3/CD:
- Impostare la Frequenza a 44100 Hz
- Impostare il formato delle tracce a 16-bit PCM
- Applicare Effetti → Normalizza a 0 dB
| Analisi | Campionare a 44.1 kHz e 16-bit PCM? |
|---|---|
| Calcolo fattore di cresta | No |
| Lettura RMS / picco | No |
| Analisi spettro / spettrogramma | No |
| Simulazione mastering / CD | Sì |
| Test anti-clipping / loudness reale | Sì |
Nota tecnica: Audacity lavora internamente in 32-bit float, quindi le analisi del picco e dell’RMS sono accurate anche senza convertire in 16-bit. Tuttavia, se vogliamo simulare il comportamento del brano su un supporto reale (CD, MP3), conviene impostare il progetto a 44.1 kHz e 16-bit PCM.
Come procedere con l’analisi:
| Valore proposto da “Amplifica…” | Significato | Azione |
|---|---|---|
| +1.13 dB | Picco a −1.13 dB | Normalizzare per portare a 0 dB |
| 0.00 dB | Picco già a 0 dB | Non serve fare nulla |
| −1.50 dB | Picco è sopra 0 (clipping) | Normalizzare per evitare saturazione |
Il calcolo del fattore di cresta può essere eseguito sia sul brano originale sia dopo la normalizzazione. Tuttavia, per confronti più realistici e tecnici, è buona pratica portare il picco a 0 dB tramite l’effetto “Normalizza”.
Esempio pratico:
- Brano A:
- Picco: −1.2 dB
- RMS: −9.2 dB
- Fattore di cresta = 8.0 dB
- Brano B (normalizzato a 0 dB):
- Picco: 0.0 dB
- RMS: −8.0 dB
- Fattore di cresta = 8.0 dB
Il valore finale è lo stesso ma nel secondo caso è più standardizzato e più confrontabile con altri brani “normali”.
Normalizzazione
Per ottenere un analisi realistica della traccia dobbiamo quindi normalizzarla.
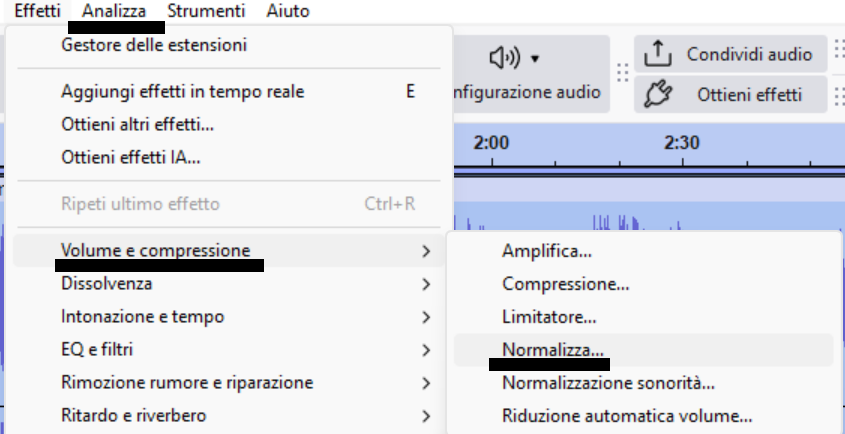
Analizziamo i 3 parametri proposti:
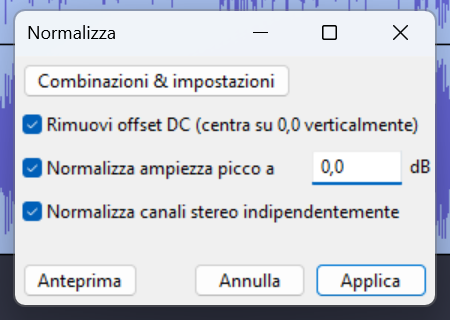
Rimuovi offset DC:
Un offset DC è una piccola deviazione della forma d’onda dal centro (zero).
In pratica, la forma d’onda invece di oscillare intorno allo 0 (come dovrebbe), è spostata verso l’alto o il basso.
🔍 È un problema tecnico che:
- può indicare un errore nel sistema di acquisizione audio (scheda audio, microfono, ecc.)
- non è udibile, ma può influenzare le elaborazioni successive (effetti, normalizzazione, compressione…)
| Situazione | Rimuovi offset DC? |
|---|---|
| Audio registrato da microfono | Sì (consigliato) |
| File importato da MP3/WAV/CD | Sì (nessun problema) |
| Sei incerto | Sì (non cambia nulla per l’ascolto) |
| Vuoi misurare un file “come ricevuto” (senza toccarlo) | No (ma è raro) |
Normalizza i canali stereo in modo indipendente:
- Se è attiva:
Audacity analizza e normalizza ogni canale (sinistro e destro) separatamente, portando ciascuno al proprio massimo di 0 dB. - Se è disattiva:
Audacity normalizza entrambi i canali insieme, mantenendo intatto il bilanciamento stereo originale, ma porta a 0 dB il canale più forte.
| Situazione | Normalizza canali indipendentemente? |
|---|---|
| Analisi tecnica canale per canale | Sì |
| Analisi del fattore di cresta su L e R | Sì (così puoi confrontare i due valori) |
| Misura della dinamica stereo separata | Sì |
| Mix musicale stereo da ascoltare/master | No (rischi di sbilanciare il mix) |
| Ascolto fedele dell’intenzione sonora | No (mantieni il mix come da origine) |
Misura del valore RMS in dB
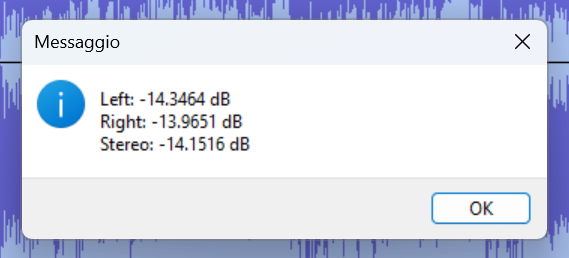
Quando si va su Analizza → Measure RMS, il plugin:
- Calcola il valore RMS della selezione corrente
- Lo mostra in decibel (dBFS), che è esattamente quello che serve
- È valido sia per tracce mono che stereo
- Il valore RMS che mostra è già in dBFS: RMS (dB)=20⋅log10(VRMS)
La formula usa il fattore 20 perché l’RMS rappresenta una grandezza di tensione, e i decibel per tensioni si calcolano come 20·log₁₀(V), essendo la potenza proporzionale al quadrato della tensione.
Nota tecnica: significato di dBFS
dBFS sta per: Decibel Full Scale, ed è una misura relativa del livello audio nel dominio digitale, cioè dentro un file WAV, MP3, FLAC, ecc.
- 0 dBFS rappresenta il livello massimo possibile che può essere rappresentato in digitale.
- Tutti gli altri livelli sono negativi, perché non è possibile superare 0 dBFS (a meno che non si stia usando 32-bit float, come visto prima).
In digitale non esistono valori “assoluti” di tensione, ma solo rapporti rispetto al massimo possibile.
| Valore | Significato |
|---|---|
| 0 dBFS | Il picco massimo, il limite superiore |
| −6 dBFS | Livello dimezzato in tensione |
| −20 dBFS | Segnale molto più debole |
| −∞ dBFS | Silenzio assoluto (zero digitale) |
Provate a lanciare la valutazione del fattore di cresta per il brano in esame.
🎧 Valutazione del fattore di cresta
Range Dinamico (Dynamic Range)
Nel primo step abbiamo calcolato il fattore di cresta medio del brano, ossia il rapporto tra il picco massimo assoluto e il livello RMS medio. Questo valore ci offre una prima indicazione della dinamica generale, ma non racconta quanto la dinamica vari nel tempo.
È qui che entra in gioco il range dinamico, inteso come la differenza tra i momenti più silenziosi e quelli più intensi nell’arco dell’intero brano. Mentre il fattore di cresta medio ci dice quanto sono “impulsivi” i picchi rispetto al livello generale, il range dinamico descrive la variabilità dell’intensità sonora nel tempo: se esistono momenti di quiete e momenti di pieno coinvolgimento emotivo, oppure se il brano “sta sempre allo stesso volume”.
Un range dinamico ampio restituisce all’ascolto respiro, naturalezza e dettaglio. Al contrario, un range troppo compresso può risultare affaticante, anche se inizialmente “forte”.
In Audacity, possiamo iniziare a esplorare la dinamica nel tempo analizzando sezioni diverse del brano o usando plugin come Youlean Loudness Meter o il TT Dynamic Range Meter, che forniscono una rappresentazione grafica del livello RMS nel tempo.
Valutare il range dinamico è fondamentale per capire quanto spazio ha lasciato l’ingegnere del suono all’espressività musicale, e quanto è stato sacrificato sull’altare della “loudness war”.
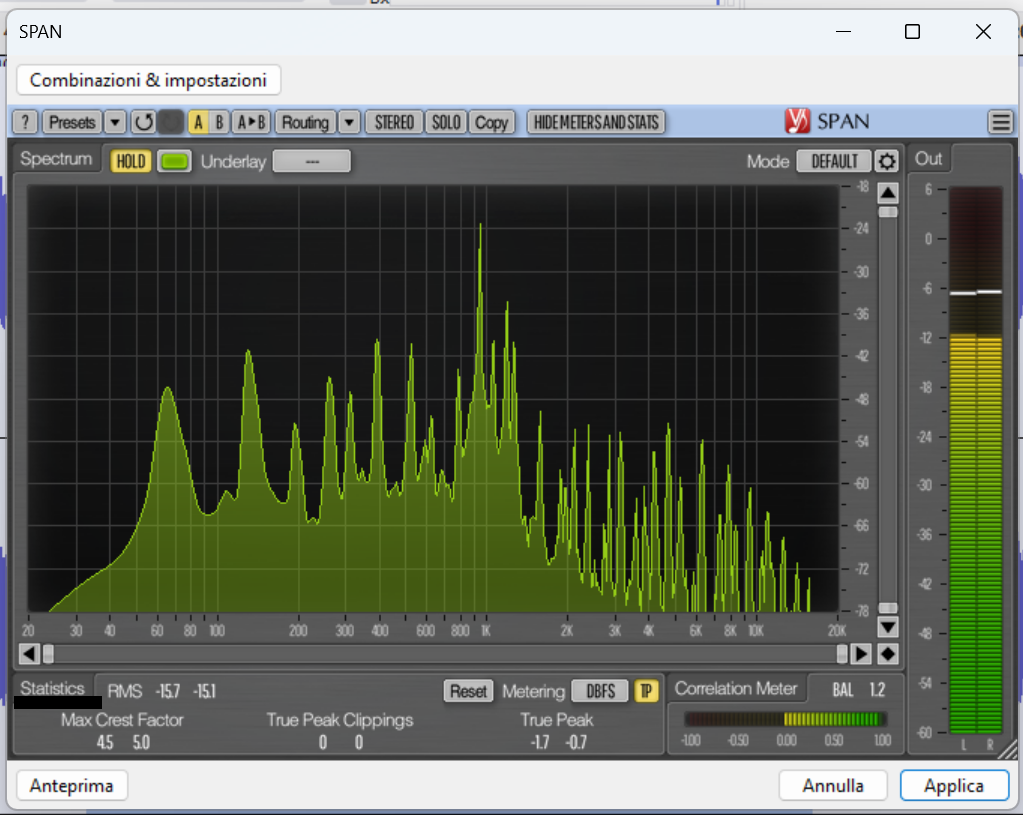
Tra i plugin gratuiti che possiamo utilizzare per effettuare questo tipo di analisi, uno dei più apprezzati è senza dubbio Voxengo SPAN. Non si limita a fornire una visualizzazione dello spettro in tempo reale: SPAN restituisce dati fondamentali come il livello RMS, il True Peak e il fattore di cresta locale, permettendoci di osservare nel dettaglio come si distribuisce l’energia sonora in diverse sezioni del brano.
Per l’ascoltatore attento, SPAN è molto più di un semplice analizzatore: è uno strumento di lettura emozionale del suono, che rende visibili gli aspetti dinamici e strutturali della musica. Ci consente di misurare con oggettività ciò che percepiamo soggettivamente, mettendo in luce quanto una traccia sia compressa, quanto respiro abbia, e come si comporti a livello stereo.
Nei prossimi passaggi vedremo come selezionare alcune porzioni rappresentative del brano, analizzarle con SPAN e trarre conclusioni tecniche e musicali dai valori rilevati.
Integrare SPAN nel flusso di lavoro di Audacity
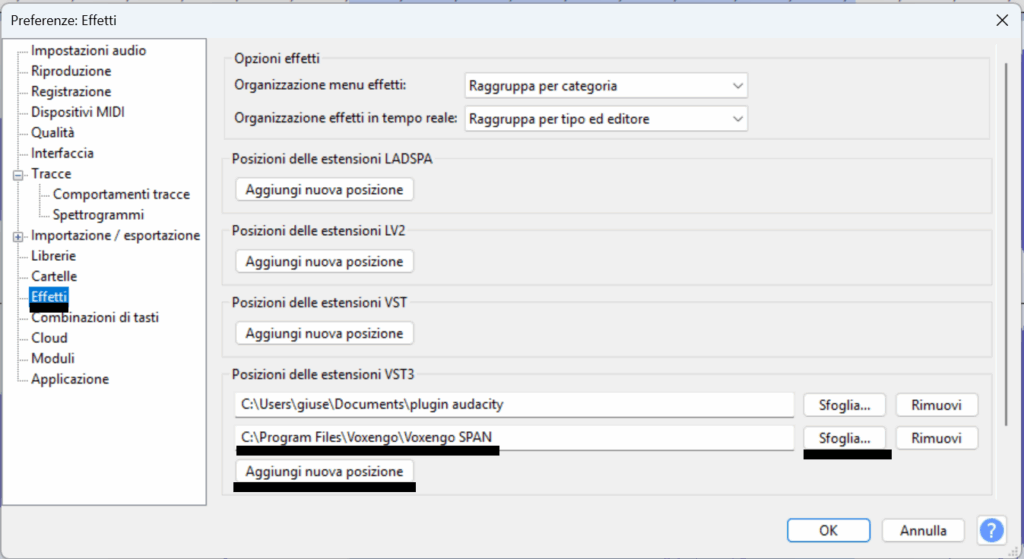
Per prima cosa dobbiamo scaricare l’estensione VST3 presso : https://www.voxengo.com/product/span/
e il manuale utente presente sulla pagina web del creatore.
Dopo averlo installato per abilitarlo come effetto su audacity bisogna annotarsi la cartella di windows in cui vengono installate le estensioni, inserirla e riavviare il software.
Troveremo l’effetto sotto:
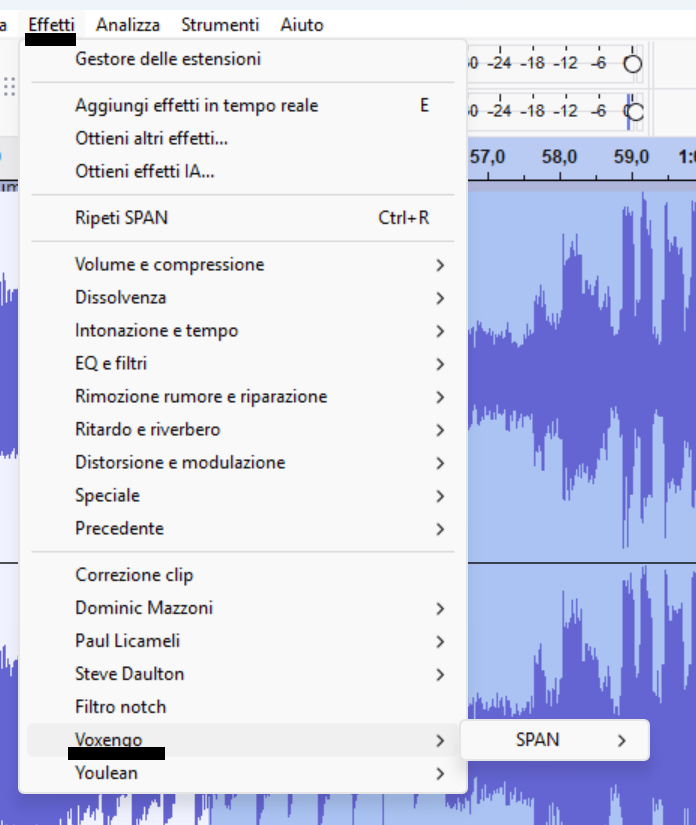
Tabella di lettura: interpretare i dati di Voxengo SPAN
| Parametro | Descrizione | Cosa ci dice |
|---|---|---|
| RMS | Livello medio del segnale in dBFS | Indica la loudness percepita di una sezione |
| True Peak | Picco massimo effettivo del segnale (anche tra campioni) | Controlla la presenza di clipping o livelli troppo vicini allo 0 dBFS |
| Crest Factor | Differenza tra True Peak e RMS (da calcolare: Peak – RMS) | Misura la presenza di transienti e la vivacità della dinamica |
| Correlation Meter | Valore tra -1 e +1 che indica la coerenza di fase tra i canali stereo | Aiuta a rilevare problemi di fase o inversioni stereo |
| BAL (Balance) | Differenza di livello tra il canale sinistro e il destro | Verifica se il mix è bilanciato o spostato verso un canale |
Analizzando più sezioni diverse del brano (intro, strofa, ritornello), è possibile confrontare i valori e ricostruire un quadro oggettivo della dinamica nel tempo. I numeri raccontano una storia: noi impariamo ad ascoltarla.
Un brano molto compresso mostrerà RMS alti, crest factor bassi, e poco contrasto tra sezioni.
Un brano naturale e dinamico avrà un range RMS molto variabile, crest factor elevati, e un True Peak ben sotto lo 0 dBFS.
La correlation dovrebbe rimanere stabile sopra 0.8; oscillazioni sotto 0.5 indicano problemi di fase stereo, specie se visibili anche all’ascolto in mono.
Il balance leggermente spostato può essere intenzionale, ma se costante e non coerente con l’immagine stereo, va indagato.
Come identificare le sezioni da analizzare nel profilo audio (forma d’onda)
In Audacity, la forma d’onda ti dà subito un’idea visiva della dinamica. Puoi quindi scegliere tre sezioni basandoti su altezza e densità dei picchi, così:
1. Sezione con picchi alti
- Appare come una forma d’onda “piena”, quasi compressa, con poca variazione.
- Di solito è un ritornello, un momento di climax o una parte masterizzata “forte”.
- Utile per vedere se c’è compressione, quanto è alto il RMS, e se il True Peak è vicino a 0 dBFS.
Obiettivo: verificare se c’è ancora spazio dinamico o se tutto è stato “spinto”.
2. Sezione con picchi medi
- Appare più equilibrata, con dinamica visibile ma non estrema.
- Potrebbe essere una strofa, una parte strumentale leggera, o un passaggio ritmico controllato.
- Utile per analizzare un punto “medio” del brano e fare da riferimento.
Obiettivo: avere un quadro generale della loudness media del brano.
3. Sezione con picchi bassi
- Appare “sottile”, con poco segnale visibile.
- Tipicamente è un’introduzione, un ponte, una coda ambient, oppure un momento delicato.
- Utile per valutare il range dinamico verso il basso: quanto si scende nei dettagli, nel silenzio.
Obiettivo: capire se il brano conserva spazio per i momenti più silenziosi.
Dopo averle scelte per ognuna:
- Selezionare ~10-30 secondi.
- Aprire SPAN.
- Annotare: RMS, True Peak, Crest Factor, Correlation, BAL.
- Poi confrontare i tre casi per stimare la dinamica reale del brano.
Nota tecnica: La durata della selezione incide moltissimo sul valore del fattore di cresta, perché: più breve è la selezione, più è probabile che picco e RMS siano vicini, più lunga è la selezione, più l’RMS medio si abbassa, e il fattore di cresta cresce.
Durata segmento
Dipende da cosa vuoi ottenere. Ecco le opzioni ideali:
| Obiettivo | Durata consigliata | Motivazione |
|---|---|---|
| Valutazione locale (es. climax, attacco, breve strofa) | 10–15 secondi | Hai un buon compromesso tra dettaglio e significatività |
| Analisi “macro” di una sezione (es. tutto il ritornello o strofa) | 20–30 secondi | Il valore RMS è più stabile, rappresenta meglio la sezione |
| Confronto tra parti diverse del brano | identica durata per tutte, es. 15 secondi ciascuna | Per confronto coerente dei valori |
Per una valutazione coerente del range dinamico, è meglio selezionare tre porzioni da circa 15 secondi ciascuna: una molto intensa, una intermedia e una più silenziosa. Questo permette di confrontare i livelli RMS, i picchi e il fattore di cresta con lo stesso riferimento temporale, evitando che la durata falsi i risultati. 15 secondi sono sufficienti per catturare il carattere della sezione, ma non troppo lunghi da diluire l’RMS con silenzi o pause.
Come preset per questo tipo di analisi si può partire con il default.
Nota:
L’analisi che segue ha valore puramente indicativo. I dati inseriti vengono interpretati sulla base di criteri tecnici generali, ma non possono sostituire l’ascolto attento né il giudizio di un esperto musicale.
Questa è una guida pensata per aiutare l’ascoltatore a orientarsi tra concetti come dinamica, bilanciamento e loudness, ma va sempre letta con spirito critico, tenendo conto del contesto artistico, del genere e delle intenzioni espressive del brano.
In altre parole: le orecchie vengono prima dei numeri.
Questa box vuole solo offrire uno strumento in più per comprendere ciò che si ascolta, non per giudicarlo.
Analisi Audiofila del Brano
RMS Medio (Average Loudness)
Il valore RMS (Root Mean Square) rappresenta la potenza percepita di un segnale audio. È una media energetica che tiene conto non solo dei picchi ma dell’intensità globale del suono nel tempo. Quando analizziamo il RMS medio di un brano intero, otteniamo un’indicazione chiara della loudness percepita complessiva.
Perchè valutarlo?
Un RMS medio troppo alto è spesso il segnale che il brano è stato masterizzato in modo aggressivo, come succede nei casi della cosiddetta Loudness War: brani iper-compressi che sembrano “forti” ma sacrificano dinamica e profondità. Al contrario, un RMS medio più basso può indicare maggiore headroom e una migliore qualità dinamica.
Misurazione
In Audacity, possiamo misurarlo usando Effetti → Amplifica: se si eleziona tutto il brano e si usi “Amplifica”, il valore proposto come guadagno massimo può dare un’idea di quanto headroom si ha , e indirettamente si può stimare l’RMS.
Cosa bisogna osservare?
- Un RMS medio tra -16 dB e -20 dBFS è considerato naturale e dinamico (tipico di brani pre-anni 2000 o jazz/classica).
- Un RMS tra -12 dB e -8 dBFS è già molto compresso (tipico del pop moderno).
- Valori oltre i -8 dBFS indicano un mastering molto “loud” e potenzialmente privo di dinamica.
Consiglio pratico
Si può provare a confrontare il brano con una versione non masterizzata (es. un mix flat o con meno compressione) oppure con brani professionali simili dello stesso genere. Ci si rende conto di quanto il loudness possa impattare sulla resa e sulla qualità percepita.
| Genere Musicale | Livello RMS Medio (dBFS) | Note |
|---|---|---|
| Musica Classica | -20 dBFS | Preserva un’ampia gamma dinamica, mantenendo le sfumature originali delle performance. |
| Jazz | -14 dBFS | Conserva una buona gamma dinamica, permettendo dettagli e sfumature espressive. |
| Rock/Pop | -12 dBFS | Bilancia la loudness con la gamma dinamica, comune nelle produzioni commerciali. |
| Heavy Metal | -7 dBFS | Tende a livelli RMS più alti per un suono più aggressivo e potente. |
| EDM (Electronic Dance Music) | -6 dBFS | Livelli RMS molto alti per massimizzare l’impatto nei club e nei festival. |
Nota: Questi valori sono indicativi e possono variare in base alle scelte artistiche e alle tecniche di mastering. È fondamentale trovare un equilibrio tra loudness e gamma dinamica per mantenere la qualità sonora desiderata.
LUFS (Loudness Units Full Scale)
LUFS è lo standard moderno per misurare la loudness percepita, usato da piattaforme come Spotify, YouTube, Apple Music, emittenti radio e TV. A differenza dell’RMS, che misura l’energia del segnale, il LUFS tiene conto della sensibilità dell’orecchio umano, rendendolo molto più rappresentativo della loudness reale.
Ogni piattaforma applica una normalizzazione automatica del volume: se il brano è più loud del target, verrà abbassato. Se è più basso, verrà lasciato così o amplificato con limiti.
Ecco perché conoscere il livello LUFS permette di:
- Masterizzare in modo ottimale per ogni destinazione
- Evitare penalizzazioni da parte delle piattaforme (che riducono il volume del brano troppo compresso)
- Mantenere coerenza tra i tuoi brani e quelli di altri artisti
| Piattaforma | Target LUFS (integrato) | Note |
|---|---|---|
| Spotify | -14 LUFS | Riduce o aumenta il gain in base al target |
| YouTube | -14 LUFS | Simile a Spotify |
| Apple Music | -16 LUFS | Valore leggermente più dinamico |
| Tidal | -14 LUFS | Compatibile con altri servizi |
| Radio FM | ~ -23 LUFS | Standard EBU R128 (come in TV europea) |
Audacity non misura i LUFS nativamente quindi è necessario esportare la traccia in formato wav e utilizzare ffmpeg.
L’installazione è molto semplice, basta scaricare l’eseguibile per windows, sbloccare il download del file non verificato, estrarre il file zip in una cartella comoda da utilizzare con il terminale di windows, può tranquillamente essere posizionata nel desktop.

Nella mia configurazione per comodità ho creato una cartella su c:
Bisogna quindi esportare nella sottocartella bin il file audio in formato wav.
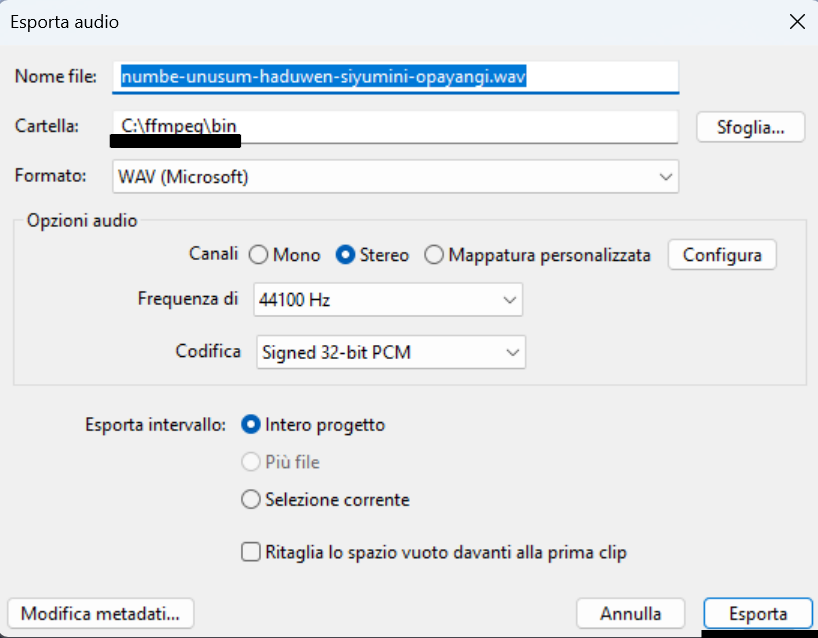
Si apre il terminale cd windows:
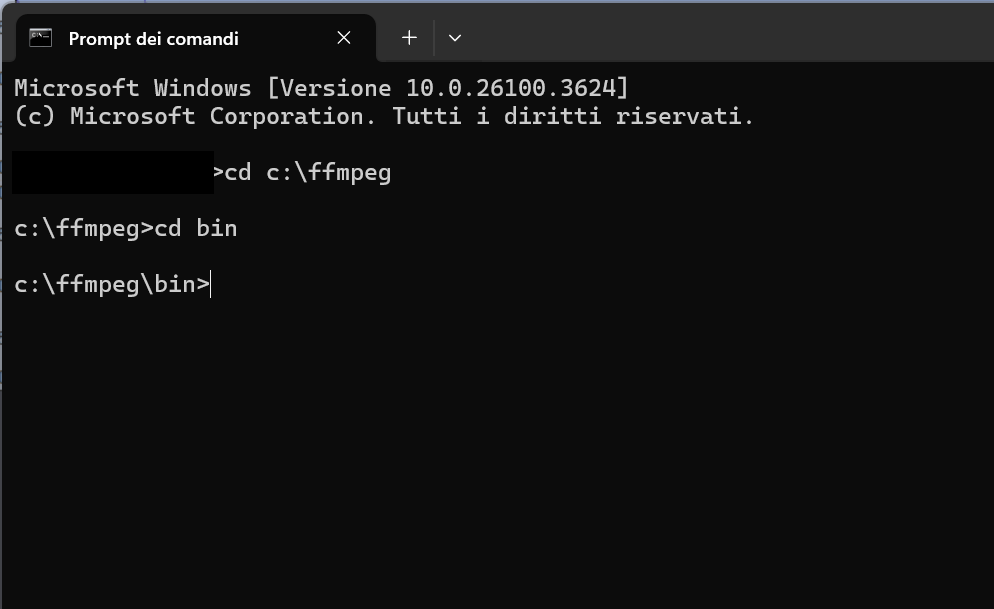
ffmpeg -i tuo_file.wav -filter_complex ebur128 -f null -Si ottiene un output di questo genere:
[Parsed_ebur128_0 @ 000001c8395d2a80] Summary:Integrated loudness:
I: -11.9 LUFS
Threshold: -22.0 LUFSLoudness range:
LRA: 8.6 LU
Threshold: -32.0 LUFS
LRA low: -17.1 LUFS
LRA high: -8.5 LUFSQuesti valori danno una panoramica precisa della loudness complessiva, dei picchi reali, e della dinamica del brano.
| Parametro | Significato |
|---|---|
| I: -11.9 LUFS | Loudness integrata: è la media complessiva percepita su tutto il brano. |
| Threshold -22.0 LUFS | Soglia usata per calcolare la loudness (valore tecnico interno). |
| LRA: 8.6 LU | Loudness Range: misura la dinamica, cioè la differenza tra parti forti e deboli. |
| LRA low: -17.1 LUFS | Il punto più silenzioso incluso nella LRA. |
| LRA high: -8.5 LUFS | Il punto più forte incluso nella LRA. |
| Threshold -32.0 LUFS | Soglia usata per individuare le parti “rilevanti” nella LRA. |
- Un LUFS integrato di -11.9 significa che il brano è più loud del target di Spotify (-14 LUFS), quindi verrà abbassato in automatico sulla piattaforma.
- Un LRA di 8.6 LU è una buona dinamica: non è troppo compresso, c’è varietà tra le parti forti e quelle più tranquille.
- Se l’LRA fosse < 5 LU, potresti sospettare compressione eccessiva (come nei brani “da loudness war”).
Per rispettare le piattaforme è meglio stare vicino a -14 LUFS integrati e mantenere un True Peak sotto -1 dBFS.
Per includere il True Peak nel report:
ffmpeg.exe -i tuo_file.wav -filter_complex ebur128=peak=true -f null -
si ottiene nell'esempio:
[Parsed_ebur128_0 @ 0000028dc5802880] Summary:
Integrated loudness:
I: -11.9 LUFS
Threshold: -22.0 LUFS
Loudness range:
LRA: 8.6 LU
Threshold: -32.0 LUFS
LRA low: -17.1 LUFS
LRA high: -8.5 LUFS
True peak:
Peak: 0.0 dBFSUn True peak di 0.0dBFS è troppo elevato e può causare distorsione nella compressione lossy (MP3, AAC).
Soluzione:
- Applicare un True Peak limiter con soglia a -1.0 dBFS
- Oppure abbassare il livello finale di 1 dB nel master
- Ricontrollare il LUFS + True Peak
| Target | LUFS | True Peak |
|---|---|---|
| Spotify | -14.0 LUFS | ≤ -1.0 dBFS |
| YouTube | -14.0 LUFS | ≤ -1.0 dBFS |
| Apple Music | -16.0 LUFS | ≤ -1.0 dBFS |
Gestione del True Peak
Obiettivo
Applicare un limiter per garantire che i picchi non superino -1.0 dBFS, proteggendo il brano da clipping o distorsione nei formati compressi.
Procedura
🔹 1. Selezionare l’intera traccia (Ctrl + A)
🔹 2. Andare su Effetti → Limiter...
Nota: questo effetto è integrato nelle versioni recenti di Audacity. Se non visibile aggiornare Audacity dal sito ufficiale.
🔹 3. Impostare così i parametri:
| Parametro | Valore consigliato |
|---|---|
| Tipo di limitazione | Soft Limit (o Hard Limit se vuoi un taglio secco) |
| Soglia (dB) | -1.0 |
| Tempo di attacco (ms) | 5.0 |
| Tempo di rilascio (ms) | 100.0 |
| Guadagno | 0.0 |
| Resa | Nuova traccia (facoltativo) |
Cliccare su “Anteprima” per sentire il risultato prima di applicare.
🔹 4. Applicare l’effetto
Ora tutti i picchi che superavano -1 dBFS saranno compressi o limitati fino a quella soglia, riducendo il rischio di sovraccarico dopo compressione MP3/AAC.
Note tecniche
Se si tagliano bruscamente i picchi (Hard Limiting)…
- Si Ottiene un livello massimo controllato (es. -1.0 dBFS)
- Ma si modifica la forma d’onda originale, cioè distorsione armonica
- Il suono può diventare “duro”, “piatto” o “squillante” (soprattutto su voce e chitarre)
Questo succede soprattutto con Hard Limit e limiti aggressivi
Se si usa un Soft Limiter o un True Peak Limiter…
- Si Lavora solo sui transienti più alti, con attacco morbido e rilascio controllato
- La forma d’onda resta più naturale
- Il suono non cambia in modo udibile (se usato con moderazione)
Un buon compromesso:
In Audacity (o in qualsiasi DAW), puoi:
Usare un Soft Limiter
| Parametro | Valore |
|---|---|
| Tipo | Soft Limit |
| Soglia | -1.0 dB |
| Attacco | 5-10 ms |
| Rilascio | 80-150 ms |
Il limiter “assorbe” i picchi in modo musicale, senza tagli netti.
Il massimo della trasparenza
Si può abbassare tutto il file con Amplify a -1.0 dB senza usare limiter → zero distorsione, ma anche meno loudness percepita.
Conclusione:
| Metodo | Sicurezza | Distorsione | Loudness |
|---|---|---|---|
| Amplify (gain negativo) | 0% | Nessuna | Più basso |
| Hard Limiter | Alta | Possibile | Più loud |
| Soft Limiter | Sicuro | Trascurabile (se ben settato) | Ottimo equilibrio |
| True Peak Limiter (VST) | Migliore | Inaudibile | Massimo loudness pulito |
True Peak Limiter
Audacity non ha un True Peak Limiter nativo (nel senso tecnico del termine), e questo è un punto importante da chiarire per chi cerca mastering trasparente e compatibile con lo standard broadcast/streaming.
Il True Peak Limiter lavora tenendo conto dei picchi che possono emergere tra i campioni digitali (intersample peaks), cosa che Audacity non calcola, perché:
- Lavora a livello di sample peak (valori numerici del file)
- Non oversampla per stimare le onde ricostruite
- Non visualizza né misura i true peaks reali
Quindi il suo “Limiter” (Effetti → Limiter…) è utile, ma non protegge da distorsioni causate da compressione lossy (es. MP3/AAC).
Per mastering professionale, bisogna usare un plugin VST esterno o passare da Audacity a una DAW più avanzata (es. Reaper, Cakewalk) ma questo esula dagli scopi di questa guida.
Scarica lo script per l’analisi LUFS + True PeakMetodo con plugin integrati in Audacity (senza VST esterni)
Abbiamo preparato un pacchetto .zip che rende semplice e accessibile l’analisi della loudness dei vostri brani audio.
All’interno si trova:
- uno script PowerShell con interfaccia grafica per caricare il file e visualizzare subito il report
- due file
.bat:avvia-analyze.bat: avvia l’analisi con un semplice doppio clicconfigura-percorso.bat: ti permette di impostare la posizione diffmpeg.exese diversa da quella predefinita
- un file di testo con le istruzioni (
howto.txt) - un file di configurazione (
config.cfg) con il percorso preimpostato diffmpeg
Nota importante per Windows:
Quando esegui il file.bat, potrebbe comparire un avviso di sicurezza (“Impossibile verificare l’origine del file”).
In tal caso, clicca su “Ulteriori informazioni” e poi su “Esegui comunque” per confermare l’esecuzione.
Tutti i file sono sicuri e non eseguono operazioni dannose.
Lo script è pensato per rendere l’analisi tecnica (LUFS, True Peak, LRA) facile anche per chi non usa la riga di comando.
Analisi nel dominio del tempo
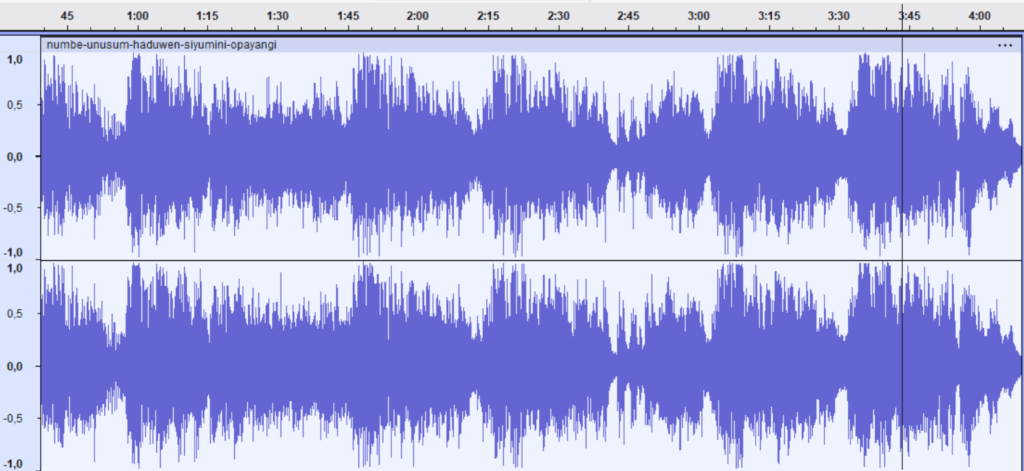
Per comprendere l’articolazione dinamica del brano nel tempo, esso è stato suddiviso in quattro sezioni consecutive, della durata di circa un minuto ciascuna (fatta eccezione per l’ultima, leggermente più breve). Le immagini riportano la forma d’onda di ciascuna sezione, ovvero la rappresentazione visiva della variazione di ampiezza del segnale audio nel tempo. Questa analisi permette di valutare l’intensità complessiva, la presenza di picchi, i vuoti dinamici, e l’uniformità del contenuto sonoro.
- Traccia A – 0:00 → 1:00: La prima sezione mostra un contenuto energetico relativamente ridotto. L’ampiezza delle oscillazioni è limitata, con pochi picchi pronunciati e una densità visiva modesta. Si tratta probabilmente di un’introduzione con arrangiamento leggero o di una fase iniziale con progressivo incremento di energia. Dal punto di vista dinamico, è utile per osservare l’avvio del brano e le strategie adottate per la costruzione della tensione sonora.
- Traccia B – 1:00 → 2:00: La seconda sezione rappresenta il punto di massima densità dinamica. La forma d’onda mostra ampiezze elevate e relativamente uniformi, con una successione continua di picchi. L’assenza di vuoti visibili e la compattezza della forma d’onda suggeriscono una fase ricca di elementi sonori sovrapposti, probabilmente corrispondente al ritornello o a una sezione portante. L’analisi di questa parte fornisce informazioni sul trattamento dinamico complessivo e sul grado di compressione utilizzato nel mix.
- Traccia C – 2:00 → 3:00: In questa sezione si nota una maggiore variabilità nell’intensità del segnale. La presenza di oscillazioni irregolari e intervalli meno densi suggerisce un’alternanza di pieni e vuoti. Dal punto di vista strutturale, potrebbe trattarsi di una strofa, un bridge o una transizione. È interessante per valutare la microdinamica e l’equilibrio tra elementi prominenti e secondari.
- Traccia D – 3:00 → fine: La sezione finale presenta una forma d’onda più regolare e con ampiezze meno esasperate rispetto alla Traccia B. La distribuzione dei picchi è omogenea ma leggermente più contenuta, suggerendo una fase di chiusura in cui si mantiene una certa energia senza saturare l’output. È utile per verificare la coerenza dinamica nella parte finale e osservare eventuali strategie di fade-out o rilassamento della tensione sonora.
- Gestione della dinamica: la successione delle quattro sezioni evidenzia un buon uso della macrodinamica per articolare l’energia del brano. La presenza di una parte “vuota” (C) tra due piene (B e D) crea respiro.
- Uniformità contro espressività: una forma d’onda troppo regolare può indicare compressione eccessiva. La sezione B mostra questa compattezza, mentre C rivela dinamiche più “vive” e naturali.
- Picchi e headroom: la forma d’onda consente di osservare la distribuzione dei picchi. Se sono costanti e al limite, si ha poco margine per la dinamica residua.
- Controllo delle transizioni: i passaggi tra le sezioni, osservabili anche nel dominio del tempo, aiutano a capire se il brano è stato prodotto con attenzione alla narrativa sonora (es. attacco graduale, rilascio morbido, cambi strutturali ben gestiti).
 🟢 Sezione iniziale – introduzione e avvio del brano In questa prima parte il segnale è visivamente più contenuto, con dinamica moderata e picchi limitati. Si tratta probabilmente di un’introduzione o di una parte preparatoria, con arrangiamento leggero. È stata selezionata per osservare come si distribuiscono le frequenze in una sezione a bassa intensità, in contrasto con i momenti più carichi del brano.
🟢 Sezione iniziale – introduzione e avvio del brano In questa prima parte il segnale è visivamente più contenuto, con dinamica moderata e picchi limitati. Si tratta probabilmente di un’introduzione o di una parte preparatoria, con arrangiamento leggero. È stata selezionata per osservare come si distribuiscono le frequenze in una sezione a bassa intensità, in contrasto con i momenti più carichi del brano.



Audacity per l’analisi delle frequenze
Analizza → Spettro di Frequenza
Come usarlo:
- Selezionare un tratto della traccia (o tutta)
- Andare su:
Analizza → Spettro di frequenza(in alcune versioni: “Plot Spectrum”) - Appare un grafico con le frequenze sull’asse X e l’ampiezza (in dB) sull’asse Y
Parametri consigliati:
- Scala: logaritmica (simula meglio l’orecchio umano)
- Dimensione FFT: da 2048 a 8192 per un buon compromesso tra precisione e dettaglio
Interpretazione:
| Banda | Frequenza | Cosa rappresenta |
|---|---|---|
| Bassi | 20–250 Hz | Punch, calore, boom |
| Medi | 250–4.000 Hz | Corpo, intelligibilità |
| Alti | 4.000–20.000 Hz | Aria, brillantezza, sibilanti |
Note tecniche sulle frequenze audio:
Dimensione di FFT:
La Dimensione FFT (Fast Fourier Transform) rappresenta il numero di campioni usati per calcolare lo spettro di frequenza in un determinato istante.
- È un parametro che controlla la risoluzione in frequenza e temporale dell’analisi.
- Più alta è la dimensione, più precisa sarà la distinzione tra frequenze vicine, ma maggiore sarà la latenza e la mediazione nel tempo.
- Tipicamente si esprime come una potenza di 2: 512, 1024, 2048, 4096, 8192, 16384…
In parole povere la Dimensione FFT è quanto in dettaglio vuoi vedere le frequenze del suono in un determinato momento.
- Valore piccolo (es. 512): vedi i cambiamenti molto veloci, ma i dettagli sulle frequenze sono meno precisi: “Vedi il suono come se avessi una lente grandangolare”
- Valore grande (es. 8192 o 16384): vedi meglio quali frequenze ci sono, ma meno bene quando cambiano: “Vedi le frequenze come se usassi uno zoom, ma con effetto rallentatore”
Esempio pratico in Audacity:
| Dimensione FFT | Frequenze Distinte | Variazioni nel tempo | Usi tipici |
|---|---|---|---|
| 512–1024 | Poco dettagliate | Molto reattivo | Analisi veloce, voci |
| 2048–4096 | Equilibrato | Reattività media | Mix, strumenti, mastering |
| 8192–16384 | Molto preciso | Lento | Misura fine, rumori, EQ |
Scala Logaritmica / Scala lineare
L’orecchio umano non percepisce le frequenze in modo lineare, ma logaritmico. Significa che un raddoppio della frequenza viene percepito come un passaggio regolare nella scala del suono.
Es:
- Da 100 Hz a 200 Hz (raddoppio)
- Da 1000 Hz a 2000 Hz (altro raddoppio): Anche se la differenza assoluta è molto diversa (100 vs. 1000), l’orecchio li percepisce come “lo stesso salto”.
Scala lineare vs logaritmica:
| Scala | Frequenze equidistanti | Percezione uditiva |
|---|---|---|
| Lineare | 100, 200, 300, 400 Hz | Intervalli uditivi non uniformi |
| Logaritmica | 100, 200, 400, 800 Hz | Intervalli uditivi costanti (ottave) |
Per questo la scala logaritmica è usata in spettrogrammi, equalizzatori, e grafici audio.
Frequenze dominanti: come riconoscerle e cosa significano
Una volta aperto lo spettro di frequenza, si potranno vedere dei “picchi” nel grafico: questi indicano le frequenze che hanno un’ampiezza più alta, quindi che dominano in quel tratto audio.
riconoscere uno squilibrio:
- Bassi predominanti (20–250 Hz) → Suono cupo, ovattato, o troppo “boomy”
- Medi predominanti (250–4.000 Hz) → Suono nasale, “telefonico”, affaticante
- Alti predominanti (4.000–20.000 Hz) → Suono frizzante ma a volte fastidioso o “sibilante”
Esempi pratici:
- Se una voce parlata ha un picco molto alto tra 5k e 8k Hz, potrebbe esserci troppa sibilanza (le “s”)
- Se una traccia musicale ha molti picchi sotto i 100 Hz e pochi sopra i 4k, potrebbe sembrare soffocata o scura
- Se il grafico è piatto o senza variazioni, potrebbe essere segno di compressione eccessiva o suono poco dinamico
Non basta guardare lo spettro una volta sola, bisogna provare a selezionare diverse parti della traccia (inizio, centro, fine) per vedere se il bilanciamento tonale cambia.
Analisi dello spettro di frequenza del brano di esempio
Intero brano
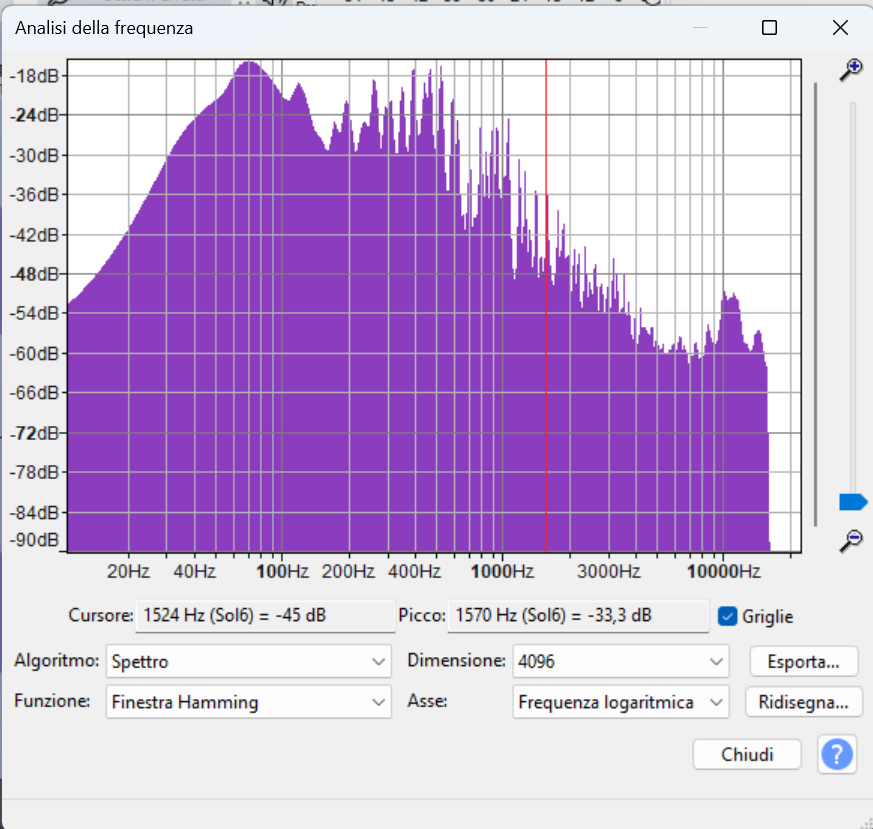
Per avere un’idea dell’equilibrio tonale generale del brano, abbiamo selezionato l’intera traccia e aperto il comando:
Analizza → Spettro di frequenza
(con scala logaritmica e Dimensione FFT = 4096).
Risultati osservati:
- Frequenze basse (20–250 Hz):
Molto presenti, con valori elevati fino a -18 dB. Il mix risulta ricco di basse frequenze, dando al brano un suono caldo, profondo, avvolgente.
→ Possibile sensazione all’ascolto: suono pieno, “boomy” o cupo. - Frequenze medie (250 Hz – 4.000 Hz):
Presenza buona ma discontinua, con un picco ben visibile intorno a 1.570 Hz (Sol6), che raggiunge i -33,3 dB.
→ Probabile zona centrale della voce o di uno strumento melodico. - Frequenze alte (4.000 – 20.000 Hz):
La curva scende progressivamente, mostrando un decadimento regolare. Un leggero rigonfiamento sopra i 10 kHz è visibile, ma nel complesso gli alti sono smorzati.
→ Sembra mancare “aria” o brillantezza: il suono risulta più “scuro” e morbido.
Il brano ha uno spettro sbilanciato sui bassi, con medi centrali in evidenza e alti attenuati. Questo crea un mix caldo e morbido, ma non brillante. Potrebbe suonare un po’ “ovattato” su alcuni impianti o cuffie.
Analisi spettrale sezionale
Dopo aver osservato la distribuzione complessiva delle frequenze nel brano intero, entriamo ora nel dettaglio analizzando quattro sezioni distinte, già evidenziate nel dominio del tempo.
Lo scopo è valutare come varia lo spettro in relazione alla struttura musicale, confrontando momenti ad alta energia, transizioni dinamiche e sezioni più leggere.
Per ciascuna sezione abbiamo selezionato circa 20 secondi e generato il rispettivo spettro con i seguenti parametri:
- FFT: 4096
- Scala: logaritmica
- Finestra: Hann
Per le analisi spettrali delle singole sezioni del brano è stata scelta la finestra di Hann, diversa da quella di Hamming utilizzata nell’analisi complessiva.
La finestratura è una tecnica fondamentale nella trasformata di Fourier: serve a ridurre gli artefatti dovuti al fatto che si analizza un segnale “tagliato” in un certo intervallo di tempo. Senza una finestra, i bordi del segnale creano discontinuità che generano frequenze spurie nello spettro (effetto chiamato leakage).
La finestra di Hann attenua in modo più deciso i bordi del segnale rispetto alla Hamming. Questo comporta due vantaggi importanti:
- Migliore attenuazione delle frequenze laterali (side lobes) → i picchi spettrali risultano più “puliti” e meno contaminati da frequenze adiacenti.
- Minor ripple (ondulazione) nella banda utile → la visualizzazione è più stabile e leggibile nei dettagli.
Di contro, la finestra di Hann ha una lobe principale leggermente più larga, cioè “spalma” un po’ i picchi più stretti, ma questo non è un problema quando si analizzano segnali complessi su intervalli brevi, come nel nostro caso.
Per questo motivo, la finestra di Hann è stata preferita per l’analisi spettrale localizzata, dove è importante separare chiaramente i picchi armonici e ottenere uno spettro più nitido.
Nella fase iniziale, dedicata all’intero brano, è stata invece usata la finestra di Hamming, più adatta a rappresentazioni globali e segnali di lunga durata.
Spiegazione teorica sulle finestre (windowing)
Quando analizziamo il contenuto in frequenza di un segnale, dobbiamo spesso “tagliarlo” in pezzi più piccoli, ad esempio per osservare come variano le frequenze nel tempo. Tuttavia, tagliare un segnale bruscamente (come fa di default la trasformata di Fourier su una finestra rettangolare) introduce discontinuità ai bordi, che causano artefatti nello spettro risultante: picchi falsi, ondulazioni e “contaminazioni” da frequenze vicine. Questo fenomeno è noto come leakage spettrale (spettro che “perde” energia in frequenze vicine).
Per ridurre questo effetto, si applica una finestra (o “window function”) prima di calcolare la trasformata. Una finestra è una funzione che pesa il segnale nel tempo, attenuando gradualmente l’inizio e la fine del tratto selezionato, così da renderlo più “morbido” ai bordi. Ogni finestra ha una sua forma e un suo comportamento in frequenza, con vantaggi e compromessi.
Finestra di Hamming
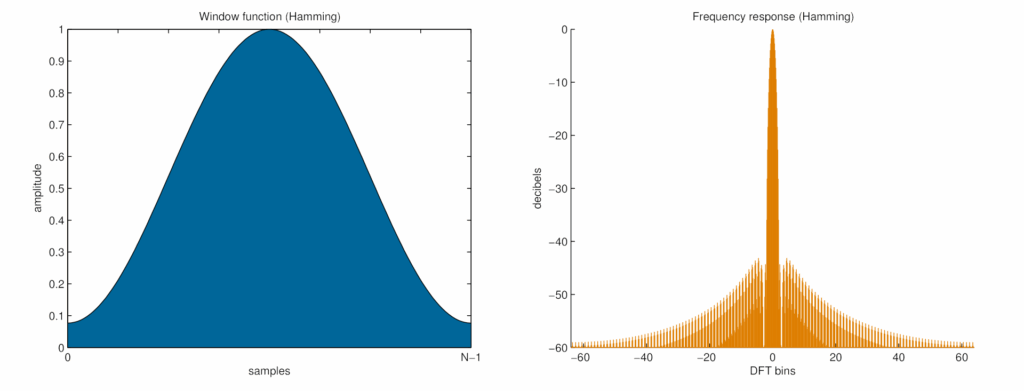
- Forma temporale: curva morbida che non scende completamente a zero alle estremità.
- Risposta in frequenza:
- Lobo principale più stretto, quindi migliore risoluzione in frequenza.
- Side lobes (picchi laterali) più elevati, che generano più leakage.
- Uso consigliato: quando è importante distinguere frequenze vicine, e si può accettare un po’ di disturbo laterale.
- Applicazione tipica: analisi su segnali più lunghi e continui, come l’intero brano.
Finestra di Hann
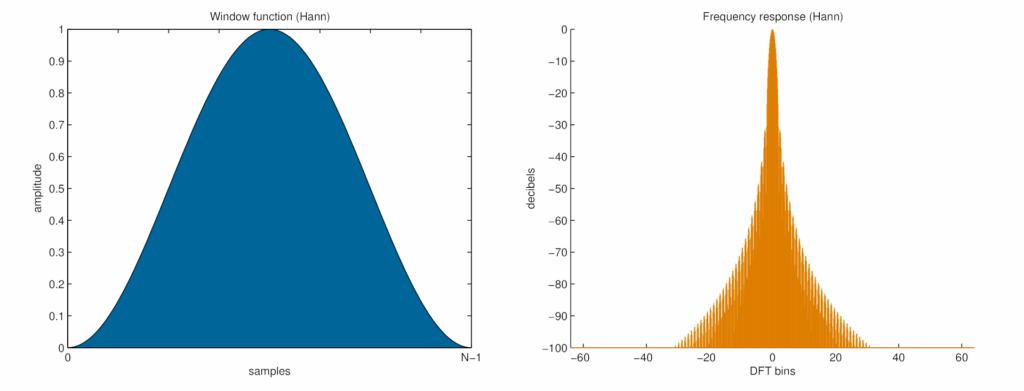
- Forma temporale: curva simile alla Hamming, ma che tocca zero alle estremità.
- Risposta in frequenza:
- Lobo principale leggermente più largo, quindi risoluzione in frequenza inferiore.
- Side lobes molto attenuate, quindi spettro più pulito, con meno leakage.
- Uso consigliato: quando serve una buona separazione dei picchi e si vuole evitare che i contenuti armonici interferiscano tra loro.
- Applicazione tipica: analisi su sezioni brevi e dettagliate del segnale, dove la chiarezza è più importante della precisione assoluta in frequenza.
Nelle analisi sezionali (es. 20 secondi o meno), il segnale ha spesso meno informazioni e una struttura più semplice, quindi l’obiettivo principale non è distinguere frequenze molto vicine, ma evitare distorsioni causate dal taglio. In questi casi:
- Le frequenze sono già ben separate naturalmente
- Le discontinuità ai bordi hanno un impatto maggiore
- Serve uno spettro pulito, non uno iper-dettagliato
La finestra di Hann è quindi perfetta perché:
- Riduce drasticamente il leakage tra le frequenze
- Attenua i bordi senza creare onde spurie
- Rende più leggibili i picchi armonici, anche se sono un po’ allargati
Per questo motivo, nella nostra analisi sezionale del brano, la Hann è preferita alla Hamming. In compenso, per l’analisi dell’intero brano (più lunga e ricca di contenuto), la Hamming garantisce migliore risoluzione spettrale, ed è più adatta.
Sezioni da analizzare nel dominio della frequenza (con finestra di Hann)
Spettro A — da 1:15 a 1:35
- Tipo di sezione: parte centrale energica, probabilmente un ritornello o sezione piena
- Obiettivo: osservare un mix bilanciato ricco di basse, medi e alti
- Cosa aspettarsi: spettro denso, picchi stabili, presenza marcata delle basse
Spettro B — da 2:40 a 3:00
- Tipo di sezione: parte più calma o transitoria
- Obiettivo: analizzare la struttura armonica in un momento con minore energia
- Cosa aspettarsi: spettro più leggero, meno ricco in basse frequenze
Spettro C — da 3:15 a 3:30
- Tipo di sezione: finale del brano
- Obiettivo: valutare la coerenza tonale nella chiusura
- Cosa aspettarsi: buona presenza dei medi, possibili variazioni negli alti
Spettro D — da 0:30 a 0:50
- Tipo di sezione: parte introduttiva
- Obiettivo: osservare l’evoluzione iniziale del contenuto spettrale
- Cosa aspettarsi: minore presenza di basse frequenze, struttura più “vuota”
Spettro A – 1:15 → 1:35
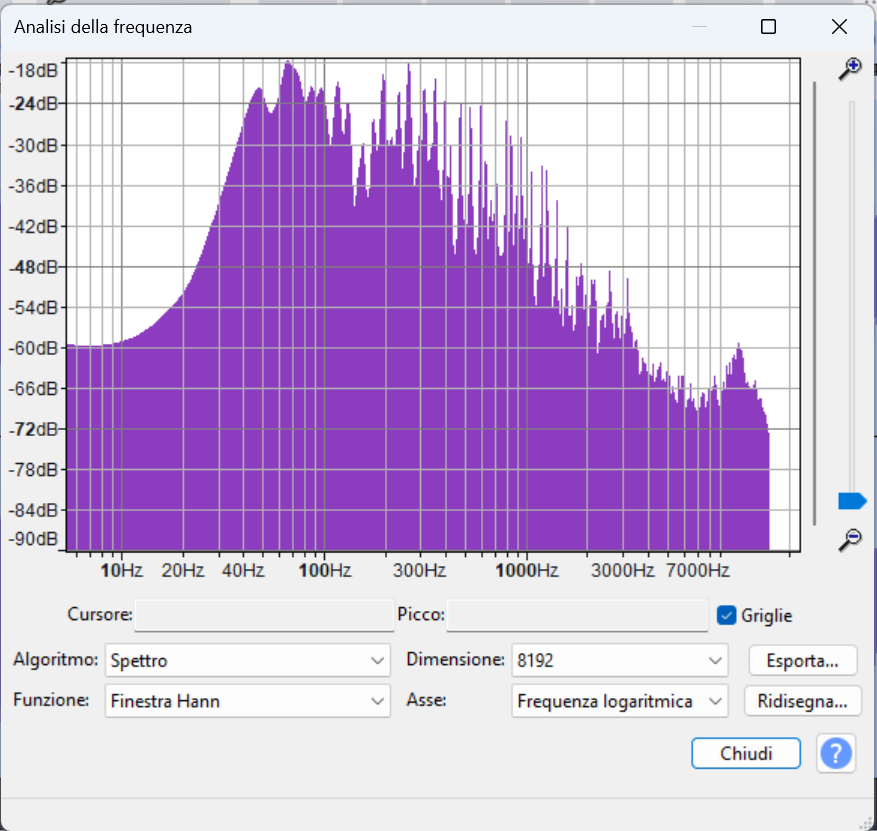
Sezione ad alta energia, probabilmente ritornello
In questa analisi spettrale, il brano mostra una forte presenza nella fascia bassa e medio-bassa, con un picco rilevante attorno ai 100 Hz e una buona densità energetica fino a circa 400 Hz.
La gamma media (400 Hz – 4 kHz) è ben rappresentata, con un andamento ricco ma non eccessivamente affollato, lasciando spazio alla voce e agli strumenti armonici.
La gamma alta (sopra i 5 kHz) è più attenuata, ma comunque presente, con un piccolo rilievo secondario visibile oltre i 10 kHz, che contribuisce all’“aria” e brillantezza della sezione.
Spettro B – 2:40 → 3:00
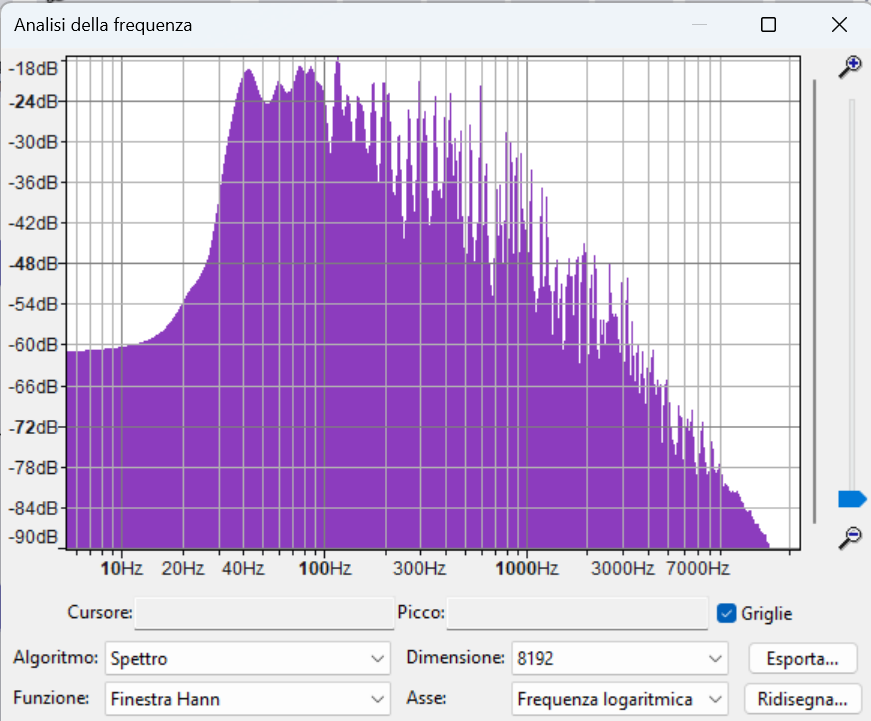
Sezione più leggera o transitoria
Rispetto allo Spettro A, questa sezione mostra un decadimento più rapido dell’energia spettrale. Le frequenze basse (intorno ai 100 Hz) restano presenti, ma la curva scende progressivamente e con maggiore pendenza nelle medie e soprattutto nelle alte frequenze, già attenuate visibilmente oltre i 4–5 kHz.
Questa struttura indica una sezione più calma o meno ricca di elementi percussivi e brillanti. L’assenza di frequenze alte suggerisce una scelta di mix più “scura” o morbida, con meno sibilanti, piatti, armoniche acute.
Le medie frequenze sono presenti ma meno dense, contribuendo a una sensazione di apertura e ariosità.
Spettro C – 3:15 → 3:30
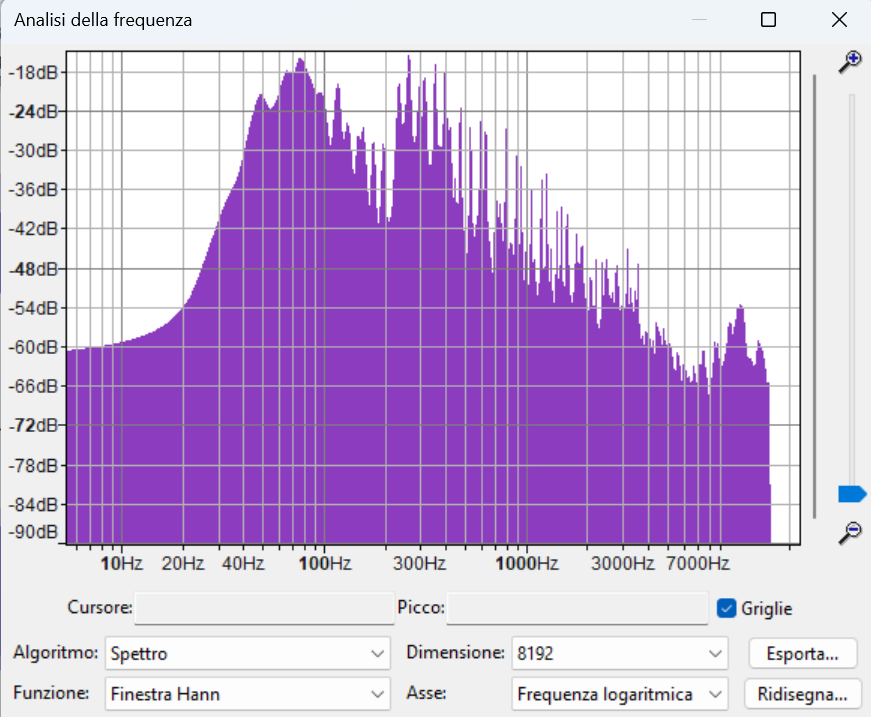
Sezione finale del brano, ritorno alla piena energia
Lo spettro C mostra una struttura molto simile a quella dello Spettro A, suggerendo che il brano ritorna a una sezione intensa e stratificata nel finale.
Le basse frequenze sono fortemente presenti, con un picco netto intorno ai 90–100 Hz, mentre le medie mantengono un profilo stabile e articolato fino ai 2–3 kHz.
A differenza di Spettro B, qui si osserva una maggiore estensione delle frequenze alte, visibile in un secondo rilievo oltre i 10 kHz, che può essere associato alla presenza di elementi brillanti o riverberi che accompagnano la chiusura del brano. Questo conferisce brillantezza e un senso di spazialità.
Spettro D — da 0:30 a 0:50
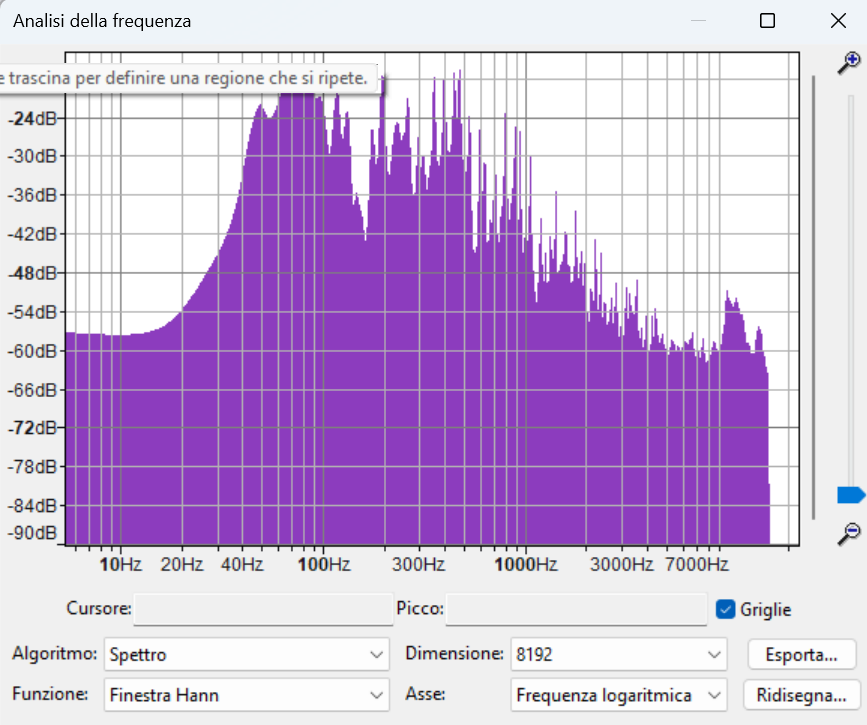
Sezione introduttiva, fase iniziale del brano
In questa fase del brano, lo spettro mostra una concentrazione marcata nelle frequenze basse, con un picco importante tra i 70 e i 120 Hz, che indica una base ritmica o armonica già definita.
Tuttavia, rispetto agli spettri successivi, si nota una minore densità nelle medie e alte frequenze. Questo suggerisce una progressione graduale: la struttura sonora non è ancora pienamente sviluppata, e il mix lascia spazio per l’ingresso di elementi successivi.
Le frequenze sopra i 5 kHz sono presenti ma poco marcate, suggerendo un ambiente ancora controllato, privo di elementi brillanti come piatti, voci sibilanti o riverberi estesi.
evoluzione tonale del brano
L’analisi spettrale in quattro punti distinti del brano permette di evidenziare in modo chiaro l’equilibrio tonale complessivo e le strategie dinamiche e timbriche adottate nella produzione.
- Spettro D (0:30–0:50) mostra una struttura semplice e bilanciata, dominata dalle basse frequenze, con una progressiva apertura verso le medie ma pochi elementi brillanti. È una fase introduttiva, dove il mix è ancora contenuto, lasciando spazio per una successiva evoluzione.
- Spettro A (1:15–1:35) segna una prima esplosione energetica: la risposta in frequenza è ricca e distribuita su tutta la banda udibile, con un bilanciamento efficace tra basse robuste, medie piene e una presenza ariosa nelle alte, che suggerisce l’ingresso del ritornello o di una parte corale.
- Spettro B (2:40–3:00) segna invece un momento di rilassamento. Le alte frequenze si attenuano più rapidamente e la curva scende più bruscamente, lasciando emergere un’atmosfera più morbida o riflessiva. Le basse restano solide, ma la struttura complessiva è meno densa.
- Spettro C (3:15–3:30) chiude il ciclo tornando a una configurazione simile a quella dello Spettro A, con una risposta bilanciata e brillante, che suggerisce un finale carico di energia. Le alte frequenze sono nuovamente presenti, conferendo spazialità e luminosità al mix.
Nel complesso, il brano segue una struttura dinamica a onde, alternando sezioni piene e brillanti a passaggi più contenuti e scuri. Questo andamento ciclico è una caratteristica tipica della produzione moderna, pensata per mantenere l’ascoltatore coinvolto attraverso variazioni timbriche, oltre che melodiche e ritmiche.
Come leggere lo spettro di frequenza: guida pratica all’interpretazione
| Zona dello spettro | Intervallo (Hz) | Cosa rappresenta | Se è molto presente… | Se è molto attenuata… |
|---|---|---|---|---|
| Sub-bassi | 20 – 60 | Profondità, vibrazione fisica | Mix potente, presenza fisica (tipico nell’elettronica) | Meno profondità, suono più asciutto |
| Bassi | 60 – 250 | Corpo, calore, kick drum, basso elettrico | Suono pieno, caldo, ritmico | Mix sottile o “vuoto” sul fondo |
| Medi-bassi | 250 – 500 | Fondamentali di strumenti e voce | Suono rotondo, “carico” | Perdita di corpo, voce debole |
| Medi | 500 – 2.000 | Intelligibilità, voce, strumenti armonici | Voce in primo piano, strumenti presenti | Mix distante, suono ovattato |
| Medi-alti | 2.000 – 4.000 | Attacco degli strumenti, chiarezza | Brillantezza e nitidezza | Suono sfocato o “impastato” |
| Alti | 4.000 – 8.000 | Sibilanti vocali, dettagli armonici | Dettaglio, aria, frizzantezza | Mix scuro, opaco |
| Ultra-alti | 8.000 – 20.000 | Aria, spazialità, riverberi | Suono ampio, brillante, hi-fi | Suono chiuso o “soffocato” |
Esempi di interpretazione pratica
- Se lo spettro decresce rapidamente dopo i 1–2 kHz, il brano potrebbe suonare scuro o ovattato.
- Se c’è un picco costante tra 3 e 5 kHz, potresti avere sibilanti vocali accentuate o suoni affaticanti.
- Se il grafico mostra una linea piatta dai 100 Hz ai 10 kHz, il mix è molto compresso e uniforme → tipico della loudness war.
- Se si vedono vuoti o buchi nello spettro, possono indicare:
- Scelte di arrangiamento (strumenti omessi)
- Problemi di EQ
- Registrazione povera di alcune bande
Non bisogna guardare solo quanto è alto il picco, ma quanto è ampia e costante la distribuzione delle frequenze. Un buon mix di solito ha una curva fluida, con presenza in tutte le bande, salvo scelte stilistiche deliberate.
Riferimenti scientifici per chi vuole andare oltre
“A Practical Guide to Spectrogram Analysis for Audio Signal Processing“ Zulfidin Khodzhaev
Questo articolo offre una guida pratica all’analisi degli spettrogrammi, discutendo l’applicazione della densità spettrale di potenza (PSD) e l’uso dello spettrogramma nell’elaborazione dei segnali audio.
“Spectral Analysis, Editing, and Resynthesis: Methods and Applications“ Michael Klingbeil
Questa dissertazione descrive lo sviluppo di software per l’analisi, l’editing e la risintesi audio, utilizzando tecniche di interpolazione dei picchi e tracciamento dei parziali.
“Introduction to Audio Analysis“ Theodoros Giannakopoulos, Aggelos Pikrakis
Questo libro fornisce un’introduzione all’analisi audio, offrendo il background teorico di molte tecniche all’avanguardia.
“Spectral Analysis and Comparison of Analog and Digital Recordings“ Hannah N. Frosch
Questo studio confronta le registrazioni analogiche e digitali attraverso l’analisi spettrale, offrendo una nuova prospettiva sulle differenze a livello di segnale.
“Application of Spectrum Analysis Technology in Music Audio Analysis“ Qiangyi Li
Questo articolo esplora l’applicazione della tecnologia di analisi spettrale nell’analisi della musica, combinando lo studio della tecnologia musicale con l’analisi spettrale.
Analisi spettrale nel tempo: spettrogramma
Lo spettrogramma è una rappresentazione grafica che mostra come le frequenze di un segnale audio variano nel tempo.
A differenza della classica analisi di Fourier, che restituisce una “foto” statica delle frequenze presenti in un tratto selezionato (Plot Spectrum), lo spettrogramma è una visualizzazione dinamica, che permette di seguire l’evoluzione del contenuto spettrale istante per istante.
Per costruire uno spettrogramma, il software divide il segnale audio in finestre di tempo sovrapposte (ad es. ogni 10–50 ms), e per ciascuna calcola una trasformata di Fourier (FFT).
Ogni “striscia” verticale del grafico rappresenta lo spettro di una finestra: mettendole in sequenza, si ottiene una mappa tempo-frequenza.
- Asse X (orizzontale): il tempo che scorre
- Asse Y (verticale): le frequenze
- Colore: l’intensità del segnale (in genere in dB), dove:
- Colori scuri o blu = frequenze deboli
- Colori caldi (giallo, arancione, rosso) = frequenze forti
Lo spettrogramma consente di:
- Visualizzare dove e quando compaiono le frequenze
- Distinguere eventi impulsivi (colpi, consonanti, attacchi di strumenti)
- Riconoscere elementi stabili nel tempo (sostegni armonici, risonanze)
- Osservare transizioni, respiri, effetti, riverberi, ecc.
- Valutare la ricchezza o povertà timbrica nel tempo
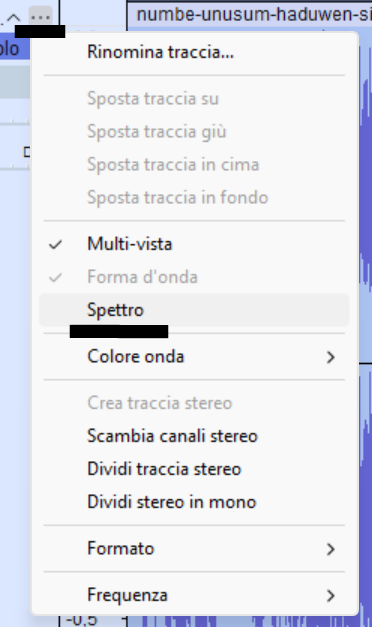
Spettrogramma in Audacity
Per visualizzare lo spettrogramma è necessario andare sui tre puntini a sinistra del nome della traccia, abilitare lo spettrogramma e poi ritornare sugli stessi tre puntini e configurare lo spettrogramma.
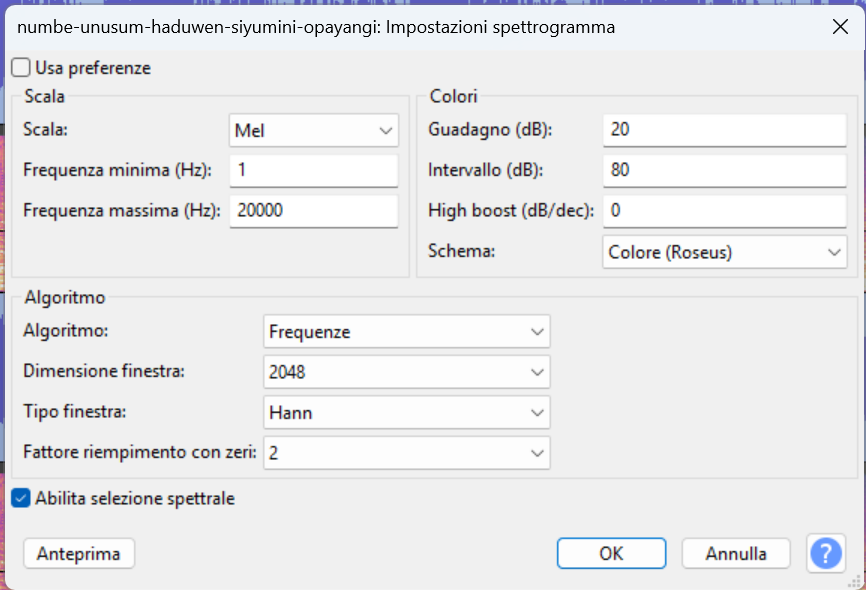
Si possono impostare delle preferenze globali anche da Menu -> Modifica -> Preferenze
Opzioni
Usa preferenze per la visualizzazione dello spettrogramma
Se non spuntiata questa opzione, Audacity userà le impostazioni “rapide” specificate solo per quella finestra, e non quelle definite nel menu Modifica → Preferenze → Spettrogrammi, altrimenti il software userà i parametri definiti nelle preferenze generali.
Scala delle frequenze
Nella finestra “Impostazioni spettrogramma” di Audacity, si può scegliere come visualizzare le frequenze sull’asse verticale (asse Y) dello spettrogramma.
Questo impatta direttamente su come si interpreta visivamente l’informazione audio, quindi è una scelta cruciale.
| Valore | Descrizione sintetica |
|---|---|
| Lineare | Frequenze equidistanti. Utile per segnali artificiali o analisi tecnica. |
| Logaritmica | Ogni raddoppio (ottava) occupa lo stesso spazio. Simula strumenti musicali. |
| Mel | Basata sulla percezione umana. Dettagliata nei medi e bassi. |
| Bark | Derivata da studi psicoacustici sul sistema uditivo umano. |
| ERB | Basata su bande critiche uditive. Molto usata in audiologia. |
| Periodo | Mostra l’inverso della frequenza (tempo di un ciclo). Poco comune. |
Spiegazione dettagliata di ciascuna scala
1. Lineare
- Frequenze distribuite in modo uniforme.
- Frequenze alte occupano molto spazio, le basse pochissimo.
- Poco utile per musica, ottima per segnali tecnici.
2. Logaritmica
- Le ottave sono equispaziate: utile se ragioni in termini musicali (es: 100 Hz → 200 Hz → 400 Hz).
- Ottima per equalizzazione, analisi tonale e strumenti musicali.
3. Mel
- Simula come il cervello percepisce l’altezza.
- Frequenze alte vengono compresse: ottima visibilità di bassi e medi.
- Ideale per voce, musica reale, analisi uditiva.
4. Bark
- Simile alla Mel, ma più focalizzata sulle bande critiche del sistema uditivo.
- Più usata in psicoacustica e ricerca sul linguaggio.
5. ERB (Equivalent Rectangular Bandwidth)
- Ancora più precisa nel modellare le bande critiche dell’udito umano.
- Utilizzata in ambiti clinici e in ricerca audio avanzata.
6. Periodo
- Mostra la durata di un ciclo (in millisecondi o secondi), non la frequenza.
- Molto poco usata nel contesto musicale.
- Utile solo in casi specifici (analisi a bassa frequenza, parlato lento, vibrazioni).
Raccomandazione pratica
| Obiettivo | Scala consigliata |
|---|---|
| Musica, voce, audio percepito | 🎯 Mel |
| Equalizzazione, strumenti | 🎯 Logaritmica |
| Analisi tecnico-ingegneristica | ⚙️ Lineare |
| Ricerca psicoacustica | 🧠 Bark / ERB |
Algoritmo di analisi: come viene calcolato lo spettrogramma
Nella finestra di configurazione dello spettrogramma di Audacity trovi una voce chiamata Algoritmo, che ti permette di scegliere il metodo con cui il software genera la rappresentazione visiva delle frequenze nel tempo.
Questa scelta incide direttamente sulla precisione e sull’aspetto dello spettrogramma, e può cambiare il modo in cui interpreti ciò che vedi.
L’impostazione predefinita è “Frequenze”, che utilizza il classico metodo basato sulla trasformata di Fourier (FFT). È adatta alla maggior parte dei casi, perché mostra con buona chiarezza la distribuzione dell’energia nelle varie bande di frequenza. Tuttavia, quando si vogliono osservare dettagli molto rapidi, come colpi di batteria, attacchi vocali o consonanti, questa modalità può risultare un po’ sfocata.
Per ottenere una visualizzazione più netta e precisa, puoi selezionare l’algoritmo “Riassegnazione”. In questa modalità, Audacity riposiziona le energie spettrali nei punti in cui “dovrebbero” trovarsi, migliorando la separazione sia in frequenza sia nel tempo. Il risultato è uno spettrogramma più definito, ideale per l’analisi di transienti o ritmiche serrate, ma che può essere più difficile da leggere a colpo d’occhio.
Infine, trovi l’opzione “Informazione EAC” (Enhanced Autocorrelation), pensata non tanto per mostrare l’energia delle frequenze, quanto per mettere in evidenza strutture periodiche all’interno del segnale. È particolarmente utile se ti interessa analizzare l’intonazione o il comportamento armonico di una voce o di uno strumento. Questa modalità evidenzia la “musicalità” nascosta nel segnale, anche se non restituisce una classica mappa tempo/frequenza.
In sintesi: la modalità Frequenze è la più comune e bilanciata, la Riassegnazione offre una precisione superiore per dettagli ritmici o consonantici, mentre EAC si presta a un’analisi più musicale, focalizzata sul timbro e l’intonazione.
Quale algoritmo scegliere? Mini-guida pratica
| Algoritmo | Usalo quando vuoi… |
|---|---|
| Frequenze | Una visualizzazione classica ed equilibrata dello spettro. Ottima per musica, voci, strumenti, analisi generale. |
| Riassegnazione | Maggiore nitidezza. Perfetta per vedere attacchi rapidi, percussioni, dettagli vocali o transitori. |
| Informazione EAC | Analizzare l’intonazione e la struttura armonica. Ideale per lo studio della voce o di melodie complesse. |
Dimensione FFT (o dimensione della finestra)
Questo parametro definisce quanti campioni audio vengono usati per ciascuna trasformata di Fourier. In altre parole, controlla quanto dettaglio in frequenza e quanto dettaglio nel tempo hai nella visualizzazione.
Bisogna quindi cercare un equilibrio tra risoluzione in frequenza e tempo, c’è un compromesso naturale in ogni analisi spettrale:
- Se si sceglie una finestra piccola (es. 256 o 512):
- Si ha buona risoluzione temporale → si vedranno i cambiamenti molto veloci (utile per attacchi di suoni, colpi, parlato)
- Ma scarsa risoluzione in frequenza → le bande si mescolano, meno precisione
- Se si sceglie una finestra grande (es. 4096, 8192 o più):
- Si hai alta risoluzione in frequenza → si può distinguere meglio armoniche vicine, picchi stabili
- Ma scarsa risoluzione temporale → si perde precisione su quando esattamente avvengono i cambiamenti
Esempio pratico
| Dimensione FFT | Effetto | Quando usarla |
|---|---|---|
| 256 – 512 | Cambi rapidi ben visibili, spettro poco dettagliato | Parlato, ritmiche, effetti sonori |
| 1024 – 2048 | Buon equilibrio tra tempo e frequenza | Musica in generale, strumenti acustici, voce |
| 4096 – 8192 | Armoniche ben separate, buona precisione frequenziale | Brani musicali complessi, analisi tonale, EQ |
| 16384+ | Altissima precisione in frequenza, tempo molto “lento” | Analisi tecnica, rumori costanti, misure stazionarie |
In questo progetto abbiamo scelto una FFT size di 4096, che rappresenta un ottimo compromesso: abbastanza precisa da separare le armoniche e allo stesso tempo abbastanza reattiva per osservare le variazioni del segnale nel tempo.
Per sezioni particolarmente brevi o dense, può essere utile aumentarla a 8192, ma valori molto alti rallentano la lettura temporale.
Tipo di finestra
Quando analizziamo un segnale a blocchi (cioè a “finestre”), il modo in cui trattiamo i bordi del blocco è fondamentale.
Senza una finestra (cioè con una rettangolare), si generano discontinuità che causano falsi picchi e una distorsione delle frequenze reali.
Applicare una funzione finestra (come Hann o Hamming) smussa i bordi del blocco, riducendo l’energia spuria.
Tipi di finestra disponibili
Rettangolare
- Nessuna finestra: il segnale viene tagliato di netto.
- Alta risoluzione in frequenza, ma massimo leakage.
- Usare solo in contesti controllati o per segnali artificiali.
Bartlett
- Forma triangolare, tocca zero ai bordi.
- Buona attenuazione, ma bassa risoluzione in frequenza.
- Usata raramente; compromesso leggero.
Hamming
- Non tocca zero ai bordi, più “morbida” della rettangolare.
- Buona risoluzione, ma con side lobes più alte.
- Ottima per analisi globali, dove si vogliono distinguere frequenze vicine.
Hann (o Hanning)
- Tocca zero ai bordi.
- Side lobes più basse → meno leakage.
- Lobo principale leggermente più largo rispetto alla Hamming.
- Ideale per analisi brevi e sezioni locali, dove conta la “pulizia”.
Blackman
- Finestre più pesanti, ottima attenuazione laterale.
- Lobo principale più largo.
- Adatta ad analisi molto pulite, ma si perde risoluzione.
Blackman-Harris
- Versione ancora più “pesante”.
- Attenua fortemente le frequenze laterali.
- Ottima per visualizzare componenti isolate senza contaminazioni.
Welch
- Parabola rovesciata: decresce gradualmente.
- Poco usata in audio, più comune in segnali naturali.
- Molto bassa risoluzione in frequenza.
Gaussiana (a = 2.5, 3.5, 4.5)
- Forma a campana, sempre centrata.
- Più alto è il parametro a, più è stretta la finestra.
- Ottima per isolare eventi localizzati nel tempo con minima distorsione.
- Molto usata in analisi vocale o di segnali impulsivi.
Riepilogo pratico
| Finestra | Leakage (distorsione laterale) | Risoluzione in frequenza | Ideale per |
|---|---|---|---|
| Rettangolare | Massimo | Massima | Segnali artificiali |
| Hamming | Moderato | Buona | Analisi globale, separazione picchi |
| Hann | Basso | Leggermente inferiore | Analisi locale, armoniche pulite |
| Blackman(-Harris) | Ottimo | Basso | Eliminare leakage, forme isolate |
| Gaussiana | Eccellente | Dipende da “a” | Segnali transitori, voce |
La scelta della finestra incide su come lo spettrogramma rappresenta le frequenze nel tempo. In questo progetto abbiamo usato la finestra di Hann, ideale per analizzare sezioni brevi del brano riducendo al minimo la distorsione laterale (leakage). Per l’analisi globale, invece, è stata utilizzata una finestra di Hamming, che offre un miglior dettaglio tra frequenze vicine, a costo di qualche artefatto in più.
Fattore di riempimento con zeri (Zero-padding)
ra i parametri disponibili nella configurazione dello spettrogramma di Audacity, figura il “fattore di riempimento con zeri”, una funzione avanzata che può influenzare in modo significativo l’aspetto visivo dello spettro, pur senza modificare il contenuto informativo del segnale.
Questa opzione agisce nel processo di calcolo della trasformata di Fourier (FFT), durante il quale Audacity analizza porzioni temporali del segnale (finestre) per determinarne il contenuto frequenziale.
Il riempimento con zeri consiste nell’aggiungere valori nulli (zeri) alla fine di ciascuna finestra di dati prima dell’elaborazione FFT. Questo non modifica il segnale né aggiunge informazioni reali, ma permette di ottenere una griglia spettrale più fitta, ovvero una maggiore risoluzione visiva del grafico risultante.
Non si tratta di un miglioramento della risoluzione effettiva in frequenza (che dipende solo dalla dimensione della finestra FFT), bensì di una tecnica di interpolazione che rende le curve dello spettro più fluide, migliorando la leggibilità dei picchi armonici.
Ad esempio, con una dimensione FFT di 2048 campioni, un fattore di riempimento con zeri pari a 2 porta la lunghezza totale dei dati analizzati a 4096 punti, di cui solo i primi 2048 contengono audio reale, mentre i restanti sono riempiti con zeri.
Il risultato è uno spettro visivamente più dettagliato, in cui è più semplice localizzare e distinguere le componenti in frequenza, anche se queste non sono realmente meglio risolte sul piano numerico.
L’uso del padding è particolarmente indicato quando:
- Si desidera una rappresentazione più fluida e continua dello spettro
- È necessario individuare con precisione la posizione di un picco armonico
- Si analizzano sezioni ricche di contenuti frequenziali sovrapposti
Al contrario, nei contesti in cui si predilige la velocità di elaborazione o si analizzano segnali molto semplici, il padding potrebbe risultare superfluo.
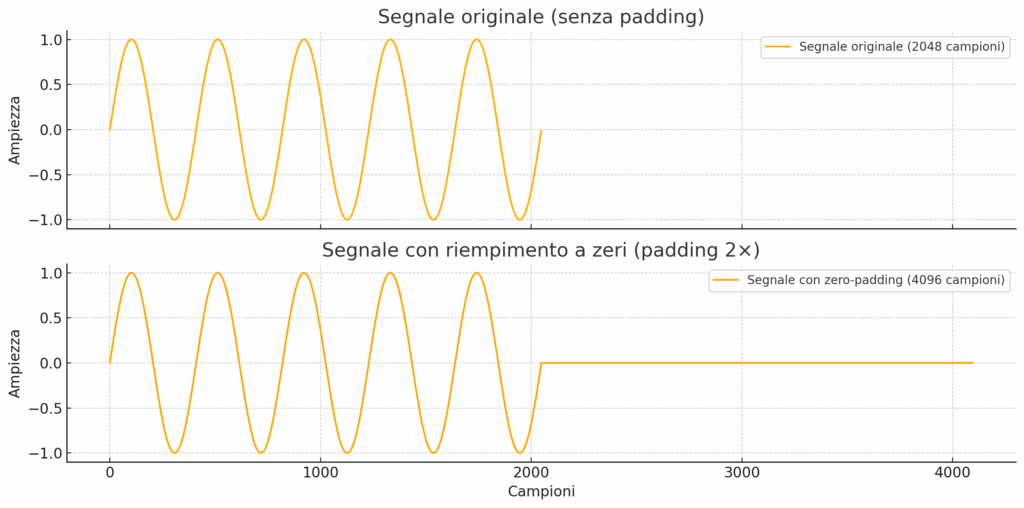
il grafico mostra cosa accade quando si applica il riempimento con zeri (zero-padding) a un segnale:
- In alto: il segnale originale, composto da 2048 campioni reali.
- In basso: lo stesso segnale riempito con zeri fino a 4096 campioni totali (padding 2×).
Come si può vedere, i dati reali restano invariati, ma viene aggiunta una sequenza piatta di zeri alla fine. Questo permette alla FFT di interpolare lo spettro su una griglia più densa, rendendo visivamente più chiari i picchi, senza introdurre nuove frequenze.
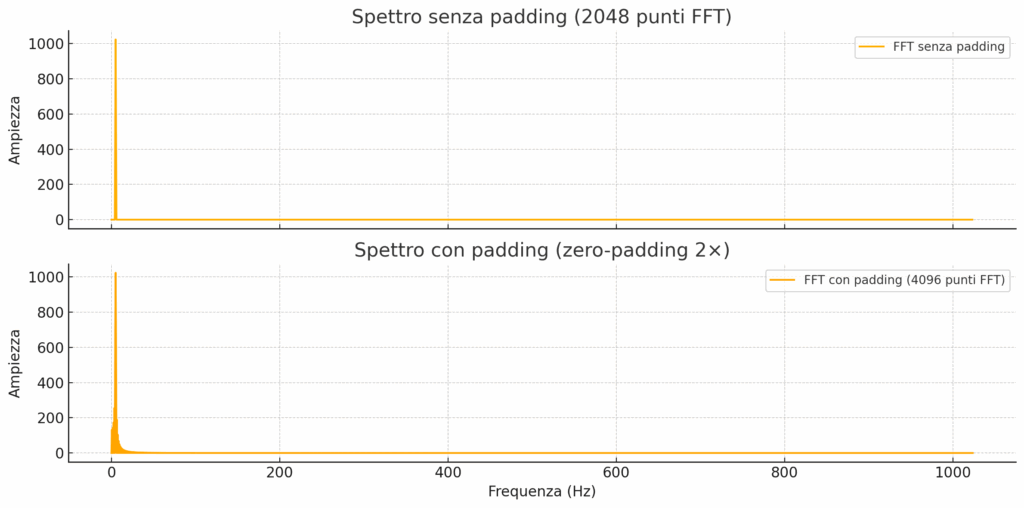
Ecco il confronto tra lo spettro senza padding (in alto) e quello con padding 2× (in basso):
- Entrambi mostrano le stesse frequenze fondamentali, perché il contenuto del segnale non cambia.
- Tuttavia, nel grafico con padding, lo spettro appare più fluido e dettagliato: i picchi sono meglio localizzati e si distinguono con maggiore precisione visiva.
Questo conferma che il riempimento con zeri migliora la leggibilità dello spettro, senza aumentare la risoluzione reale.
L’effetto visivo di “sbordo” attorno ai picchi nello spettro con padding è dovuto alla maggiore densità dei punti FFT. Questo consente di osservare meglio la forma reale del picco, inclusi i lobi laterali generati dalla finestratura (in questo caso Hann). Non si tratta di distorsione, ma di una rappresentazione più fedele del contenuto armonico del segnale.
Valori consigliati
| Fattore di riempimento | Effetto visivo |
|---|---|
| 1 (nessun padding) | Spettro più grossolano, curve scalettate |
| 2–4 | Buon compromesso tra leggibilità e velocità |
| >4 | Spettro estremamente fluido, ma senza nuovo dettaglio reale |
Analisi spettrografica dettagliata
 spettrogramma 0-35-sec
spettrogramma 0-35-sec









Per analizzare a fondo la struttura e le trasformazioni sonore del brano “numbe-unusum-haduwen-siyumini-opayangi”, abbiamo suddiviso l’intera traccia in intervalli temporali regolari e per ognuno abbiamo generato uno spettrogramma con Audacity. Lo spettrogramma è uno strumento visivo potentissimo: ci permette di “vedere” la musica, rappresentando su un’immagine la distribuzione dell’energia sonora nel tempo (asse orizzontale), nelle frequenze (asse verticale) e nell’intensità (colore). Colori più chiari indicano maggiore energia: il bianco e il giallo segnalano presenza sonora intensa, mentre i toni scuri (rosso, viola, nero) indicano assenza o silenzio.
0:00 – 0:35
L’apertura è densa di energia alle basse frequenze, ben visibile nella fascia compresa tra 100 Hz e 1000 Hz. Questi suoni gravi, presenti fin da subito, conferiscono una base solida e profonda alla sezione iniziale del brano. Notiamo però anche l’emergere graduale di frequenze più alte, come a suggerire che qualcosa sta per accadere. L’inizio è quindi costruito con una certa tensione latente, e lo spettrogramma lo mostra chiaramente.
0:35 – 1:10
Entrano nuove componenti ritmiche, percepibili nei pattern regolari e ripetuti nelle bande medie e alte. La trama si fa più complessa: non solo è aumentata la densità sonora, ma l’energia si distribuisce in modo più ampio. Il passaggio tra le due immagini (0:00–0:35 e 0:35–1:10) mostra un’evoluzione chiara: da una base grave e semplice a una struttura stratificata, che coinvolge tutto lo spettro.
1:10 – 1:45
Siamo ormai dentro un flusso sonoro articolato: molte linee armoniche appaiono in parallelo, come piccoli gradini verticali che attraversano le frequenze medie (1000–5000 Hz). Il ritmo è sostenuto e ben scandito. Le zone più chiare, tendenti al bianco, indicano una maggiore intensità rispetto ai segmenti precedenti. Lo spettrogramma racconta visivamente una fase centrale del brano, in cui si alternano densità e pause in modo molto dinamico.
1:45 – 2:20
In questa porzione avviene una sorta di riflessione sonora. Le bande chiare si diradano, lasciando maggiore spazio a zone meno intense. È come se il brano stesse “respirando”, lasciando un momento di sospensione prima di ripartire. Lo spettrogramma mostra chiaramente questa flessione energetica, soprattutto nella fascia alta.
2:20 – 2:55
Un ritorno improvviso della pienezza sonora. Qui si evidenziano netti pattern ritmici, quasi geometrici, che si alternano tra 500 Hz e 7000 Hz. Sono presenti armoniche molto regolari, che conferiscono al suono una sensazione quasi meccanica. È interessante notare la presenza di bande verticali molto fitte: indicano eventi brevi e ripetuti, probabilmente percussioni elettroniche o effetti digitali.
2:55 – 3:30
La varietà e complessità del tessuto sonoro raggiungono uno dei picchi massimi. Lo spettrogramma è fittissimo di dettagli: linee orizzontali a più livelli, alternate a fasce verticali, mostrano la sovrapposizione di suoni continui e suoni impulsivi. È una sezione centrale molto elaborata, e lo spettrogramma la traduce in un’immagine che sembra quasi un disegno astratto.
3:30 – 4:00
Si percepisce un lento e progressivo calo dell’energia. Le frequenze più alte iniziano a scomparire, lasciando spazio a un ritorno delle basse. È come se il brano si stesse preparando alla chiusura. Lo spettrogramma mostra questa transizione con una evidente diminuzione dei colori brillanti nelle fasce alte, segno di una riduzione delle componenti acute.
4:00 – 4:10
La coda del brano è caratterizzata da una forte rarefazione. Lo spettrogramma evidenzia ampie zone scure, e le poche componenti rimaste si concentrano nei registri bassi e medio-bassi. È una conclusione morbida e graduale, che riporta l’ascoltatore al silenzio. Visivamente, si passa da un’immagine piena e vivace a una molto più tranquilla e vuota, come a chiudere un ciclo.
Oltre all’analisi dell’intensità delle frequenze che ci permette di capire l’andamento del brano possiamo fare altre osservazioni dallo spettrogramma.
Per prima cosa, possiamo cercare la presenza di linee orizzontali parallele e regolari: queste rappresentano le armoniche. Si riconoscono facilmente come serie di linee ben distinte ed equidistanti tra loro. Quando le troviamo, soprattutto nelle frequenze medio-basse, siamo quasi certamente in presenza di un suono armonico stabile. L’equidistanza indica la presenza di una frequenza fondamentale accompagnata dalle sue armoniche superiori, che solitamente derivano da note tenute da una voce o da strumenti melodici.
Nel nostro spettrogramma, ad esempio a partire dal minuto 1:10, è ben visibile una ricca presenza di armoniche tra 500 Hz e 2000 Hz. Queste componenti conferiscono musicalità al brano e ne costituiscono la base tonale, rendendolo letteralmente “sonoro” all’orecchio.
Le strisce verticali strette e luminose, che si ripetono in alcune sezioni (per esempio intorno al minuto 2:20 e ancora tra 2:55 e 3:30), corrispondono a eventi sonori brevi e ritmici: colpi di batteria, suoni percussivi o impulsi digitali. La regolarità delle distanze tra queste bande ci fornisce informazioni sulla struttura ritmica e, spesso, sul tipo di drum machine o loop impiegati.
Se queste strisce sono molto ravvicinate e costanti, indicano un ritmo serrato e denso; se invece sono più distanziate, ci suggeriscono una rarefazione ritmica, momenti più tranquilli o sospesi.
Lo spettrogramma ci racconta anche l’evoluzione armonica del brano. In alcuni punti, osservando con attenzione (magari ingrandendo le immagini), si distinguono profili a “scala” o a “dente di sega”, con bande orizzontali che salgono o scendono gradualmente. Questo tipo di figura è tipico dei suoni che modulano nel tempo, come un sintetizzatore in glissando, una voce che cambia intonazione o un arpeggio in movimento.
Un esempio molto chiaro lo troviamo tra 2:55 e 3:30, dove compaiono delle piccole “piramidi rovesciate” ripetute nel tempo: è probabile che rappresentino un fraseggio ciclico, con salite e discese di tonalità.
Un’altra informazione visiva molto utile riguarda le “esplosioni di energia sonora”. Queste si manifestano come macchie bianche larghe, che coprono porzioni ampie dello spettro, spesso dai 200 Hz fino oltre gli 8000 Hz. Sono i momenti di massima intensità emotiva, in cui la composizione raggiunge un picco.
Nel nostro brano, una di queste zone si osserva chiaramente tra 3:10 e 3:30.
Al contrario, le zone nere o quasi nere, prive di profili visibili, corrispondono a pause, silenzi o rarefazioni sonore. Questi momenti hanno spesso una funzione narrativa: creano tensione, servono da preludio a un’esplosione successiva, o offrono respiro all’ascoltatore.
Nell’ultima parte del brano, tra 4:00 e 4:10, notiamo proprio questa rarefazione, che coincide con una chiusura graduale e controllata.
Lo spettrogramma ci aiuta anche a individuare i pattern che si ripetono nel tempo. Osservando la sezione tra 1:10 e 1:45, notiamo gruppi di bande e linee che si ripresentano quasi identici, a intervalli regolari. Questi pattern visivi sono indizi chiari di sezioni strutturate del brano, come ritornelli o loop ricorrenti. Possiamo letteralmente “vedere” il ritorno di un ritornello, o capire dove termina una strofa e inizia la successiva.
Infine, lo spettrogramma ci permette di individuare la presenza di manipolazioni digitali, effetti, o distorsioni audio. In alcune sezioni si osservano bande sfumate e irregolari, soprattutto nelle alte frequenze tra 5 kHz e 15 kHz. Le linee non sono più nette e parallele, ma frastagliate, ondulate, a volte quasi granulose, e possono sfumare verso l’alto senza una chiara interruzione.
Questo accade quando un suono non è stabile, ma cambia continuamente nel tempo: modulazione, riverbero digitale, filtraggio dinamico, saturazione o pitch shifting sono solo alcuni dei possibili effetti che producono queste forme visive.
Ne troviamo un buon esempio tra 0:35 e 1:10 e di nuovo attorno a 3:45. Questi pattern non sono un errore: al contrario, sono segni distintivi del sound design moderno, in cui la manipolazione elettronica è parte integrante della creatività.